dimension reduction
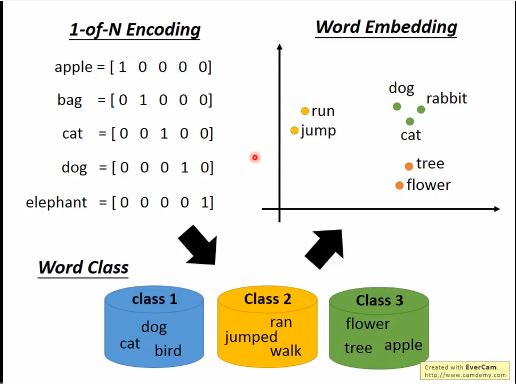
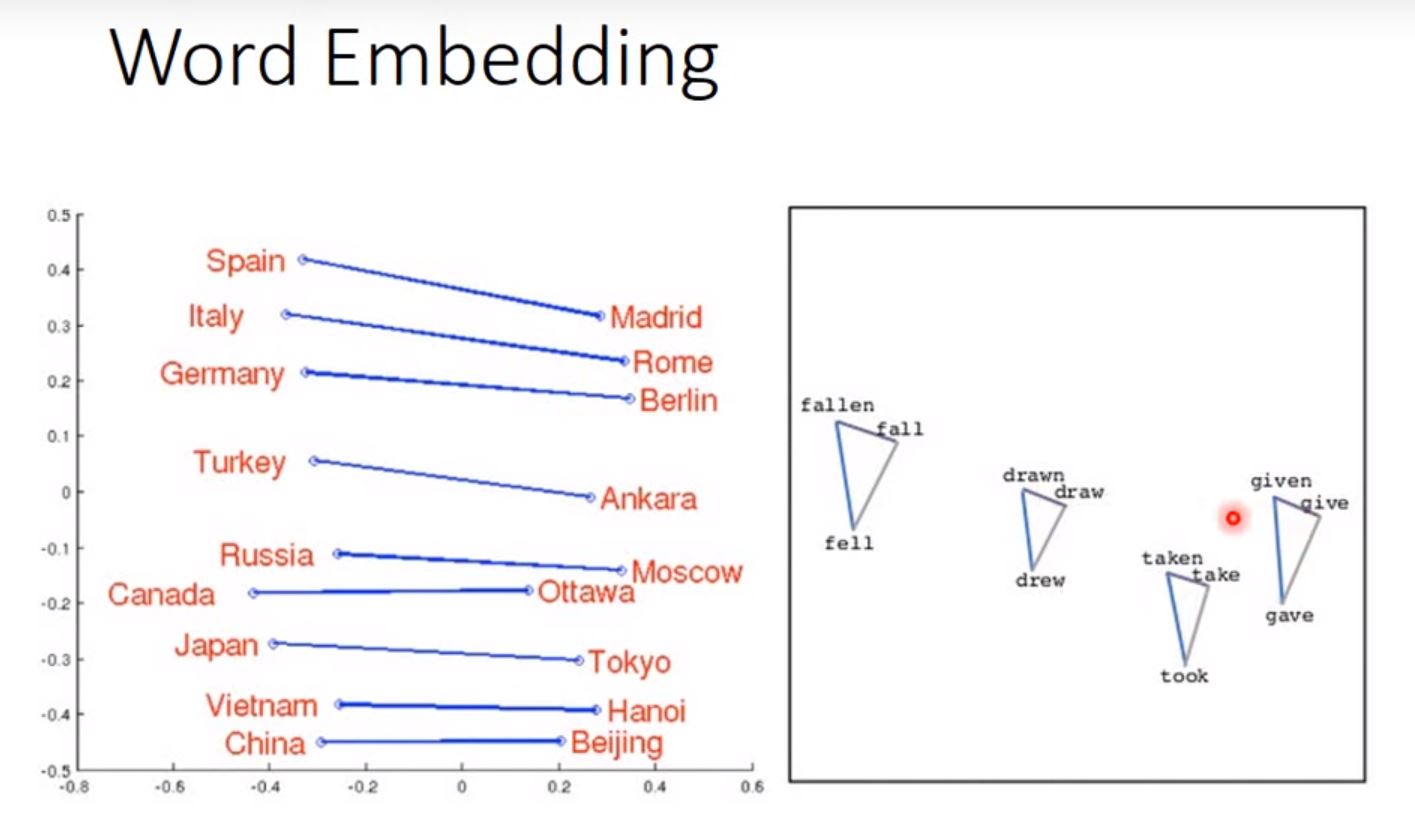
word Embedding
- Machine learn the meaning of words from reading a lot of documents without supervision.
- Generating Word Vector is Unsupervised
- A word can be understood by its context.
How to exploit the context?
- count based: If two words $w_i$ and $w_j$ frequently co-occur, $V(w_i)$ and $V(w_j)$ would be close to each other.(Glove Vector)
$V(w_i) \cdot V(w_j) \to N_{i,j}$, where number of times $w_i$ and $w_j$ in the same document.
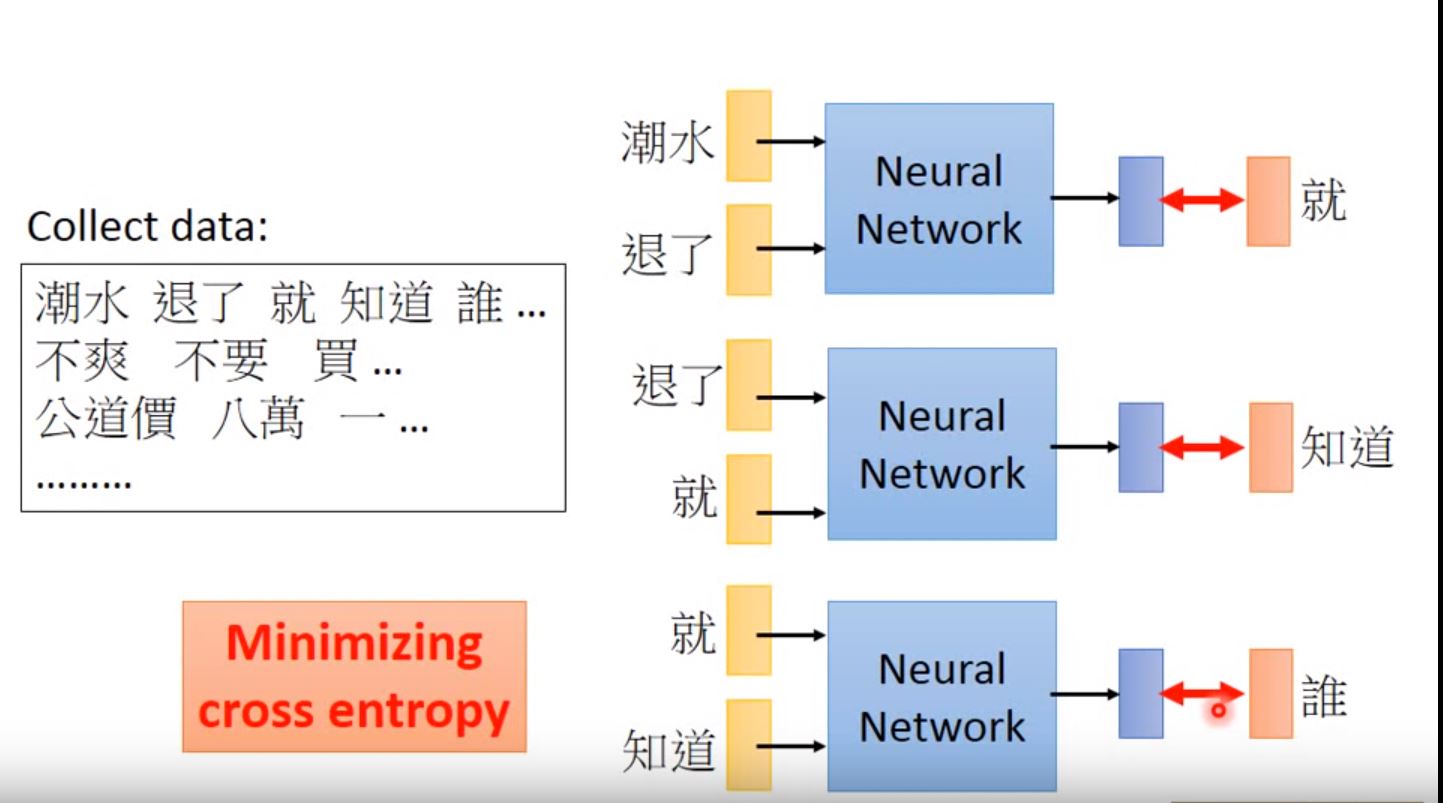
- prediction based: predict next word based on previous words.
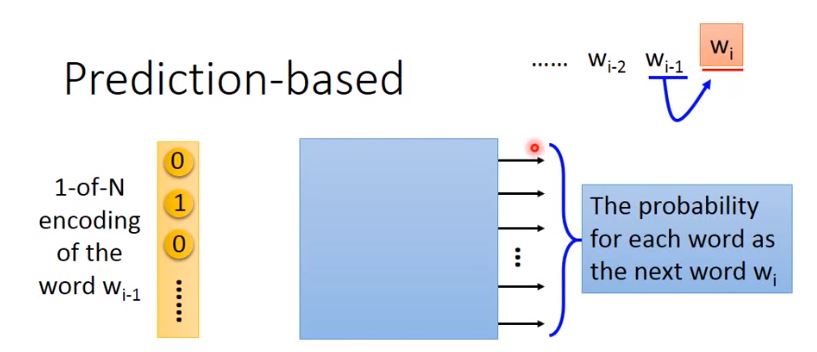
- take out he input of the neurons in the first layer.
- use it to represent a word w
- word vector. word embedding feature: V(w)
具有相同上下文的单词具有相近的分布
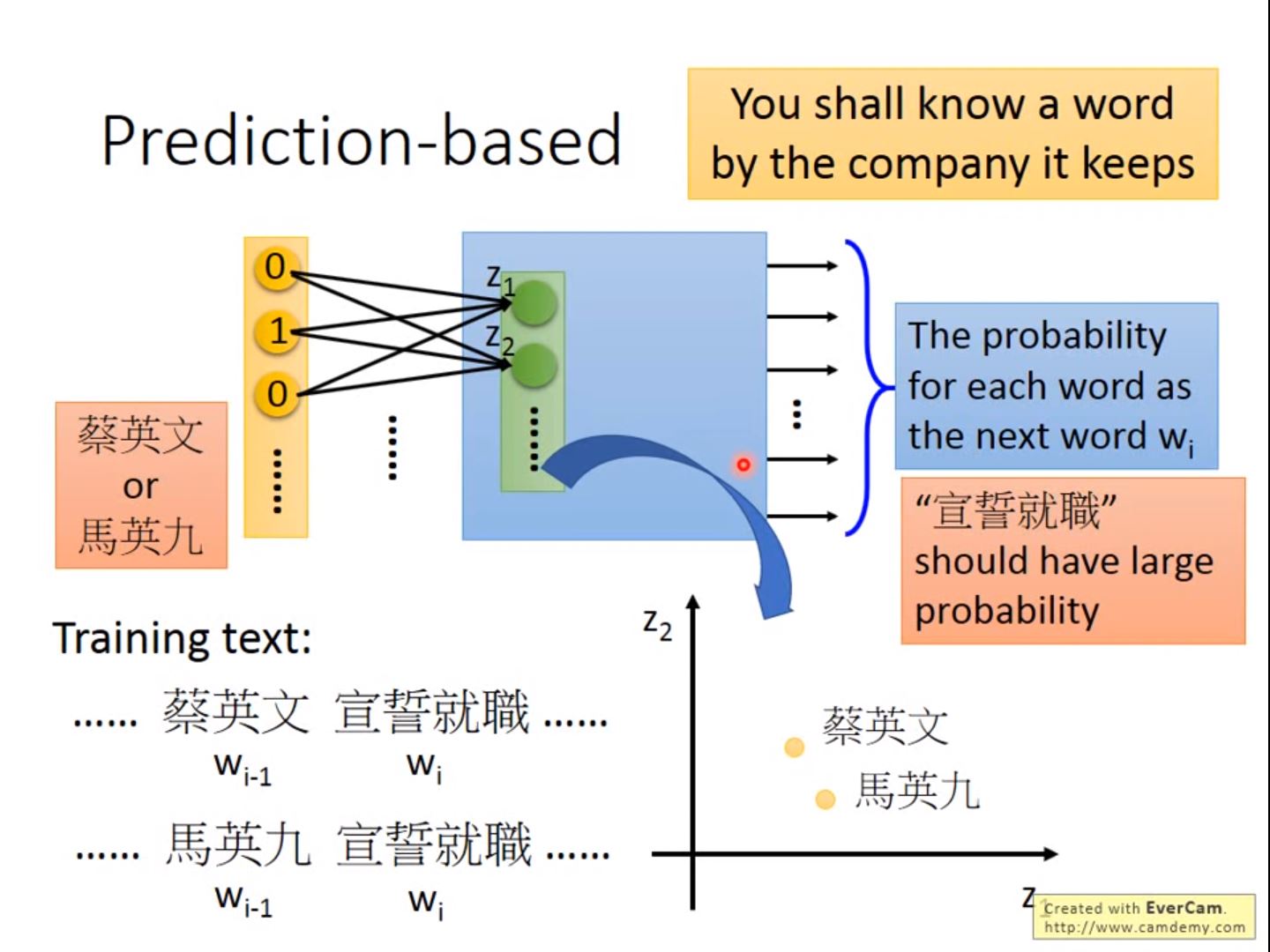
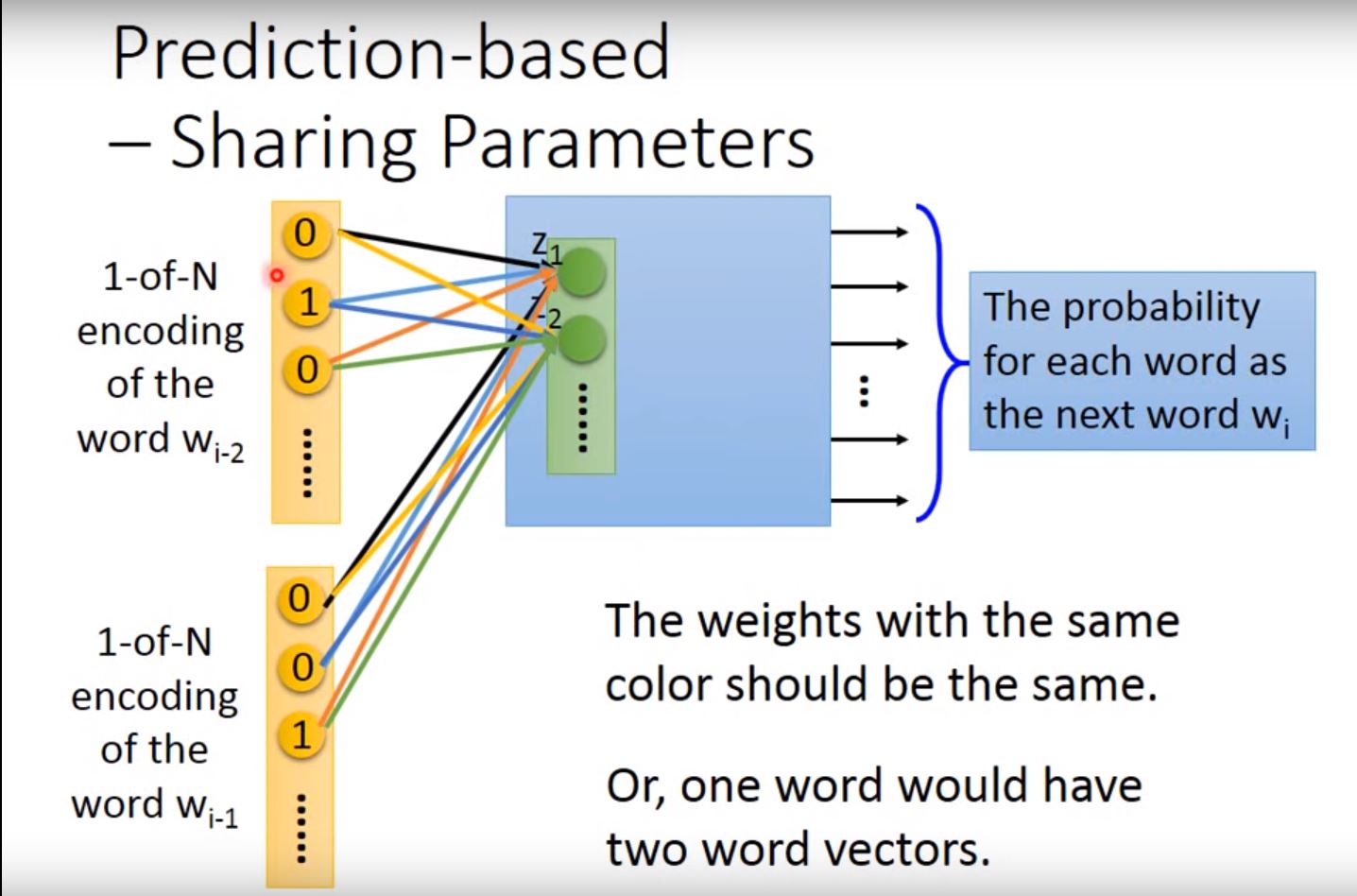
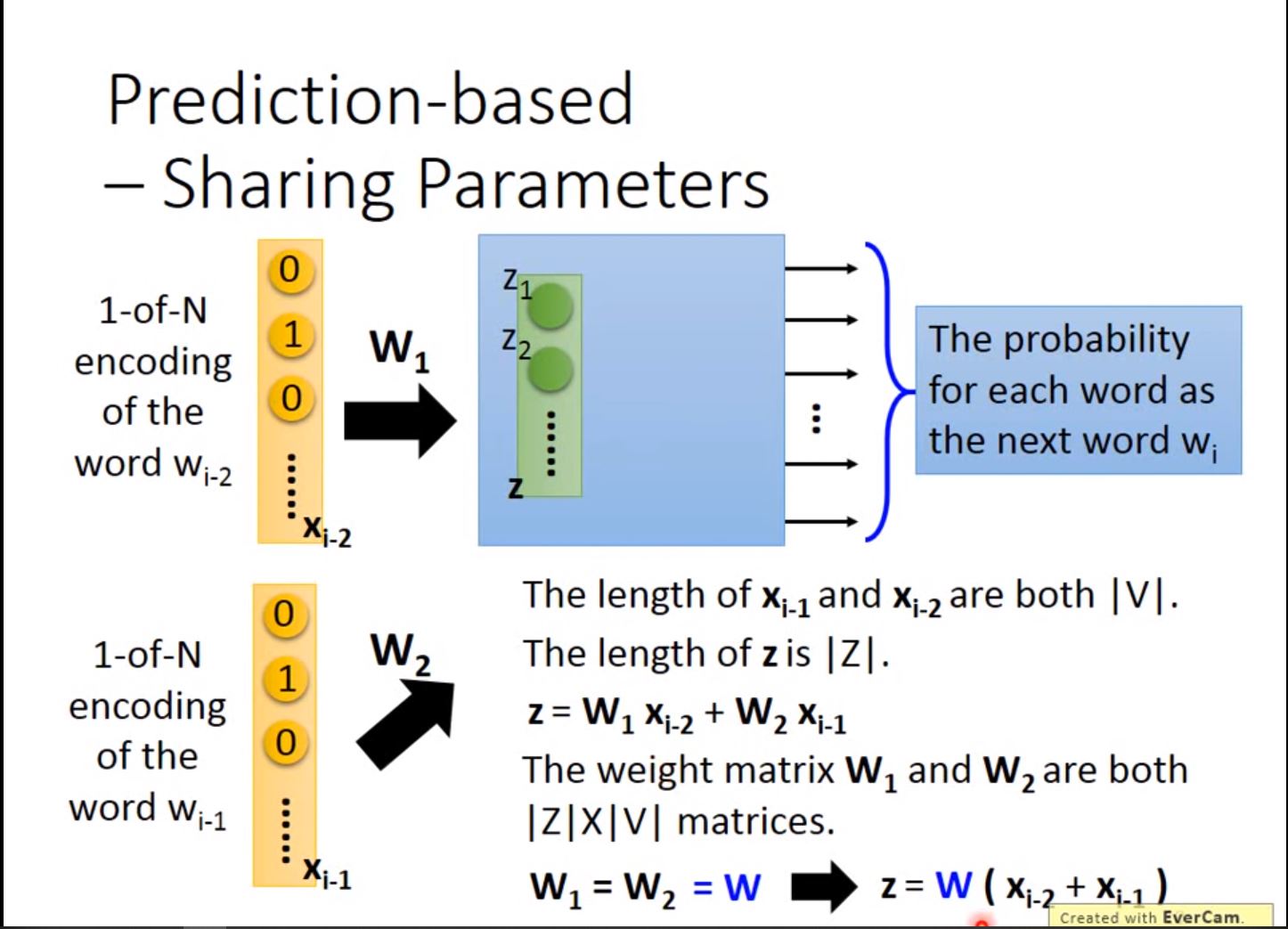 如何让两个weight一样?一样有什么好处?
如何让两个weight一样?一样有什么好处? - Given the same initialization
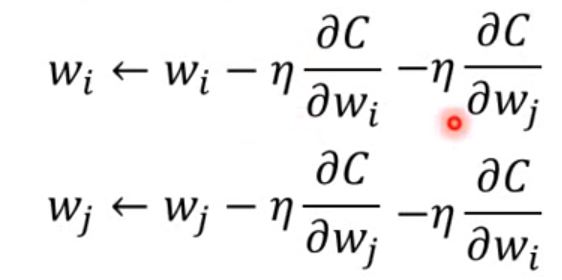
- cross entropy:
two class:
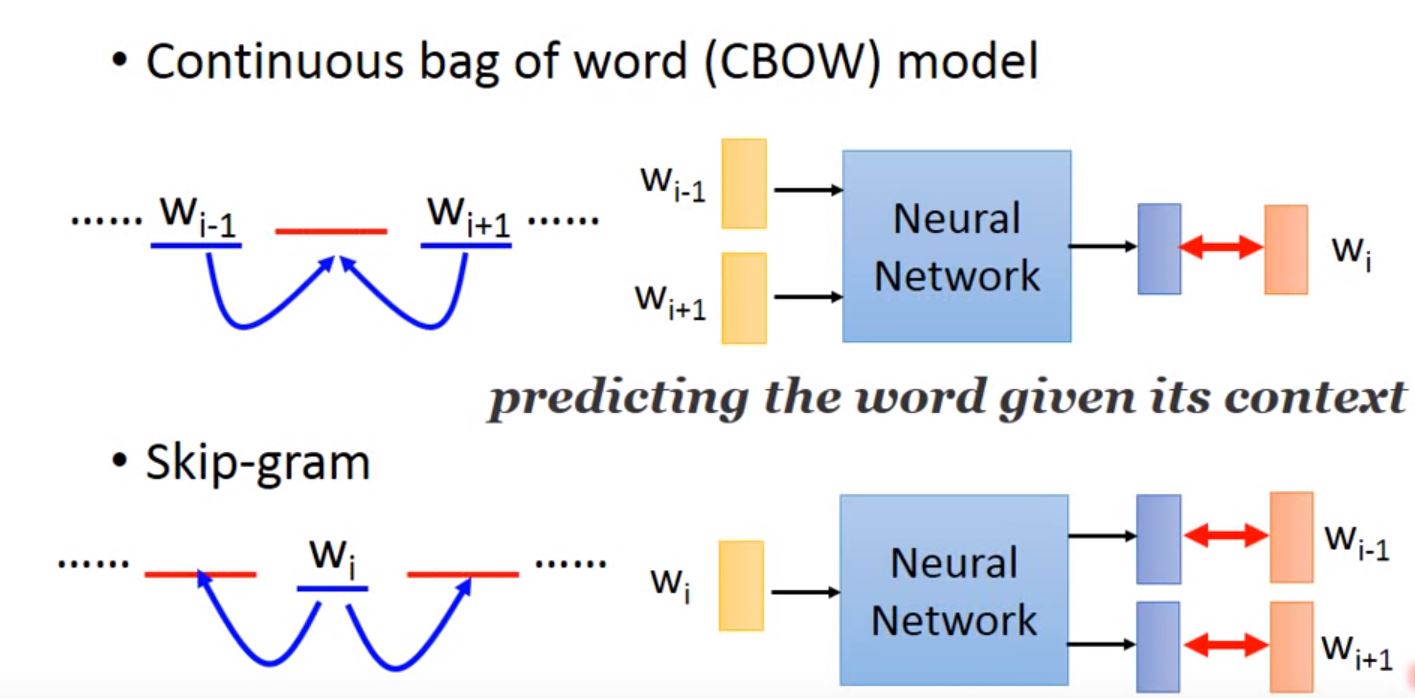
- Cbow
- skip-gram
 结构信息:结构,包含关系等
结构信息:结构,包含关系等

document Embedding
