Naive Bayes
见 https://dinry.github.io/%E8%A5%BF%E7%93%9C%E4%B9%A6day13/, 这里再复习一下。
朴素贝叶斯的关键组成是贝叶斯公式与条件独立性假设。为了方便说明,我们举一个垃圾短信分类的例子。
"在家日赚百万,惊人秘密..."
$p(垃圾短信 \mid "在家日赚百万")∝p(垃圾邮件)p("在家日赚百万"\mid 垃圾短信)$
由条件独立性假设:
$p("在家日赚百万" \mid J)=p("在","家","日","赚","百","万"∣J)=p("在" \mid J)p("家"\mid J)p("日"\mid J)p("赚"\mid J)p("百"\mid J)p("万"\mid J)$
上面每一项条件概率都可以通过在训练数据的垃圾短信中统计每个字出现的次数得到,然而这里有一个问题,朴素贝叶斯将句子处理为一个 词袋模型(Bag-of-Words, BoW) ,以至于不考虑每个单词的顺序。这一点在中文里可能没有问题,因为有时候即使把顺序捣乱,我们还是能看懂这句话在说什么,但有时候不行,例如:
我烤面筋 = 面筋烤我 ?
那么有没有模型是考虑句子中单词之间的顺序的呢?有,N-gram就是。
N-gram
N-gram简介
在介绍N-gram之前,让我们回想一下**“联想”**的过程是怎样发生的。如果你是一个玩LOL的人,那么当我说“正方形打野”、“你是真的皮”,“你皮任你皮”这些词或词组时,你应该能想到的下一个词可能是“大司马”,而不是“五五开”。如果你不是LOL玩家,没关系,当我说“上火”、“金罐”这两个词,你能想到的下一个词应该更可能“加多宝”,而不是“可口可乐”。
N-gram正是基于这样的想法,它的第一个特点是某个词的出现依赖于其他若干个词,第二个特点是我们获得的信息越多,预测越准确。我想说,我们每个人的大脑中都有一个N-gram模型,而且是在不断完善和训练的。我们的见识与经历,都在丰富着我们的阅历,增强着我们的联想能力。
N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。

N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 $Bi-gram(N=2)$ 和 $Tri-gram(N=3)$,一般已经够用了。例如在上面这句话里,我可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}
N-gram中的概率计算
假设我们有一个由n个词组成的句子 $S=(w_1,w_2,⋯,w_n)$,如何衡量它的概率呢?让我们假设,每一个单词 $w_i$ 都要依赖于从第一个单词 $w_1$ 到它之前一个单词 $w_{i−1}$的影响:
$p(S)=p(w_1w_2⋯w_n)=p(w_1)p(w_2 \mid w_1)⋯p(w_n \mid w_{n−1}⋯w_2w_1)$
是不是很简单?是的,不过这个衡量方法有两个缺陷:
- 参数空间过大,概率 $p(w_n \mid w_{n−1}⋯w_2w_1)$ 的参数有 $O(n)$ 个。
- 数据稀疏严重,词同时出现的情况可能没有,组合阶数高时尤其明显。
为了解决第一个问题,我们引入马尔科夫假设(Markov Assumption):一个词的出现仅与它之前的若干个词有关。
$p(w_1⋯w_n)=\prod p(w_i \mid w_{i-1}⋯w_1)=\prod p(w_i \mid w_{i-1}⋯w_{i-N+1})$
- 如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为 Bi-gram:$p(S)=p(w_1w_2⋯w_n)=p(w_1)p(w_2 \mid w_1)⋯p(w_n \mid w_{n-1})$
- 如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为 Tri-gram
N-gram的N可以取很高,然而现实中一般 bi-gram 和 tri-gram 就够用了。
那么,如何计算其中的每一项条件概率 $p(w_n \mid w_{n−1}⋯w_2w_1)$ 呢?答案是 极大似然估计(Maximum Likelihood Estimation,MLE),说人话就是数频数:

N-gram 的用途
用途一:词性标注

用途二:垃圾短信分类

用途三:分词器

用途四:机器翻译和语音识别

N-gram中N的确定
为了确定N的取值,《Language Modeling with Ngrams》使用了 Perplexity 这一指标,该指标越小表示一个语言模型的效果越好。文章使用了华尔街日报的数据库,该数据库的字典大小为19,979,训练集包含 38 million 个词,测试集包含 1.5 million 个词。针对不同的N-gram,计算各自的 Perplexity。
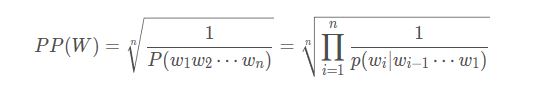 结果显示,Tri-gram的Perplexity最小,因此它的效果是最好的。
结果显示,Tri-gram的Perplexity最小,因此它的效果是最好的。
N-gram中的数据平滑方法
上面提到,N-gram的N越大,模型 Perplexity 越小,表示模型效果越好。这在直观意义上是说得通的,毕竟依赖的词越多,我们获得的信息量越多,对未来的预测就越准确。然而,语言是有极强的创造性的(Creative),当N变大时,更容易出现这样的状况:某些n-gram从未出现过,这就是稀疏问题。
n-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有20k个词,那么两两组合其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的n-gram概率都不为0。它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。
 关于N-gram的训练数据,如果你以为 “只要是英语就可以了”,那就大错特错了。文献《Language Modeling with Ngrams》**的作者做了个实验,分别用莎士比亚文学作品,以及华尔街日报作为训练集训练两个N-gram,他认为,两个数据集都是英语,那么用他们生成的文本应该也会有所重合。然而结果是,用两个语料库生成的文本没有任何重合性,即使在语法结构上也没有。
这告诉我们,N-gram的训练是很挑数据集的,你要训练一个问答系统,那就要用问答的语料库来训练,要训练一个金融分析系统,就要用类似于华尔街日报这样的语料库来训练。
关于N-gram的训练数据,如果你以为 “只要是英语就可以了”,那就大错特错了。文献《Language Modeling with Ngrams》**的作者做了个实验,分别用莎士比亚文学作品,以及华尔街日报作为训练集训练两个N-gram,他认为,两个数据集都是英语,那么用他们生成的文本应该也会有所重合。然而结果是,用两个语料库生成的文本没有任何重合性,即使在语法结构上也没有。
这告诉我们,N-gram的训练是很挑数据集的,你要训练一个问答系统,那就要用问答的语料库来训练,要训练一个金融分析系统,就要用类似于华尔街日报这样的语料库来训练。
N-gram的进化版:NNLM
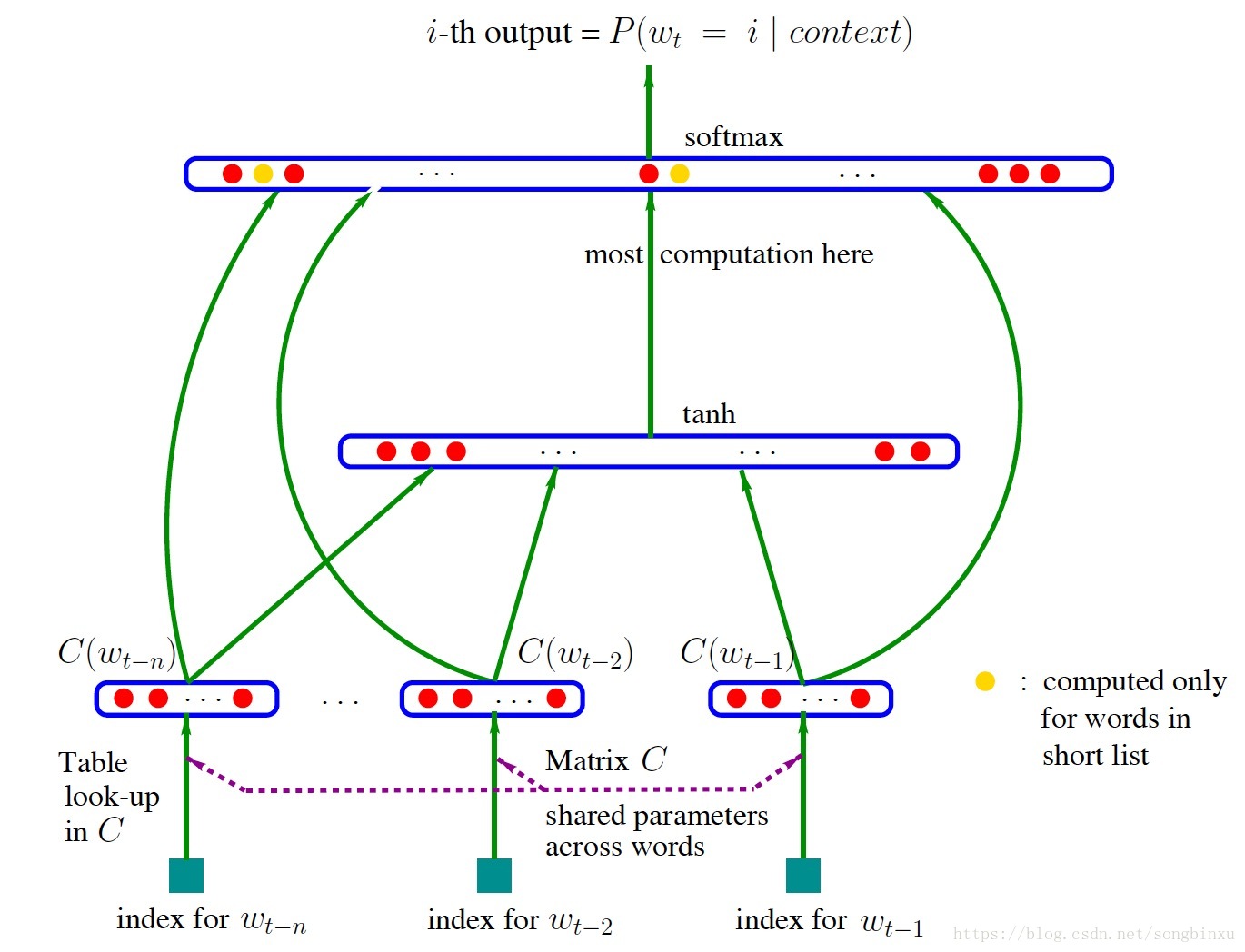
NNLM 即 Neural Network based Language Model,由Bengio在2003年提出,它是一个很简单的模型,由四层组成,输入层、嵌入层、隐层和输出层。模型接收的输入是长度为nn的词序列,输出是下一个词的类别。首先,输入是单词序列的index序列,例如单词 I 在字典(大小为 $\mid V \mid$)中的index是10,单词 am 的 index 是23, Bengio 的 index 是65,则句子“I am Bengio”的index序列就是 10, 23, 65。嵌入层(Embedding)是一个大小为 $\mid V \mid \times K$ 的矩阵,从中取出第10、23、65行向量拼成 $3\times K$ 的矩阵就是Embedding层的输出了。隐层接受拼接后的Embedding层输出作为输入,以tanh为激活函数,最后送入带softmax的输出层,输出概率。
NNLM最大的缺点就是参数多,训练慢。另外,NNLM要求输入是定长n,定长输入这一点本身就很不灵活,同时不能利用完整的历史信息。
NNLM的进化版:RNNLM
针对NNLM存在的问题,Mikolov在2010年提出了RNNLM,其结构实际上是用RNN代替NNLM里的隐层,这样做的好处包括减少模型参数、提高训练速度、接受任意长度输入、利用完整的历史信息。同时,RNN的引入意味着可以使用RNN的其他变体,像LSTM、BLSTM、GRU等等,从而在时间序列建模上进行更多更丰富的优化。
http://www.fit.vutbr.cz/~imikolov/rnnlm/thesis.pdf
Word2Vec
https://www.jianshu.com/p/e91f061d6d91