决策树定义
决策树是基于输结构来进行决策的一类常见的机器学习分类方法。
解决问题
“当前样本属于正类吗?”
“这是好瓜吗?”
“它的根蒂是什么形态”
决策过程的最终结论(叶子节点)对应了我们所希望的判定结果:好瓜 or 坏瓜
结构
1.一个根节点和若干个内部节点:分别对应一个属性测试
2.若干个叶节点:对应决策结果
j决策树学习的目的是为了产生一棵泛化能力强的决策树,基本流程遵循“分而治之”:

递归返回条件:
- 当前节点包含的样本全属于同一类别,无需划分
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
- 当前节点包含的样本集合为空,不能划分。
ID3
信息熵:
熵是度量样本集合纯度最常用的一种指标,代表一个系统中蕴含多少信息量,信息量越大表明一个系统不确定性就越大,就存在越多的可能性,即信息熵越大。
假定当前样本集合D中第K类样本所占的比例为 $p_k(k=1,2,...,\mid y\mid)$, 则D的信息熵为:
$Ent(D)=-\sum_{k=1}^{\mid y \mid}p_{k}log_{2}p_{k}$
信息熵满足下列不等式:
$0 \leq Ent(D) \leq log_{2}\mid y \mid$ ,
$0 \leq p_k \leq 1$, $\sum_{k=1}^np_k=1$
其中$y$表示D中的样本类别数。
ID3推导(max-value)
若令 $\mid y \mid=n,p_k=x_k$, 那么信息熵 $Ent(D)$ 可以看作一个n元实值函数,即
$Ent(D)=f(x_1,...,x_n)=-\sum_{k=1}^{n}x_{k}log_{2}x_{k}$, 其中:$0 \leq p_k \leq 1$, $\sum_{k=1}^np_k=1$.
引入拉格朗日乘子 $\lambda$求最值:
$L(x_1,...,x_n,\lambda)=-\sum_{k=1}^{n}x_{k}log_{2}x_{k}+\lambda(\sum_{k=1}^nx_k-1)$
$\frac{\partial L(x_1,...,x_n,\lambda)}{\partial x_1}=-log_2x_1-x_1 \cdot \frac{1}{x_{1}ln2}+\lambda=0$
$\lambda=log_2x_1+\frac{1}{ln2}$
同理:
$\lambda=log_2x_1+\frac{1}{ln2}=log_2x_2+\frac{1}{ln2}=...=log_2x_n+\frac{1}{ln2}$
so: $x_1=x_2=...=x_n=\frac{1}{n}$
最大值与最小值需要验证:
- $x_1=x_2=...=x_n=\frac{1}{n}$ 时:$f=-n \cdot \frac{1}{n}log_2\frac{1}{n}=log_2n$
- $x_1=1,x_2=x_3=...=x_n=0$ 时: $f=0$
所以为最大值
ID3推导(min-value)
Assume:
$f(x_1,...x_n)=\sum_{k=1}^ng(x_k)$
$g(x_k)=-\sum_{k=1}^{n}x_{k}log_{2}x_{k}$, $0 \leq p_k \leq 1$
求 $g(x_1)$ 的最小值,首先求导:
$\frac{d(g(x_1))}{dx_1}=-log_2x_1-\frac{1}{ln2}$
$\frac{d^2(g(x_1))}{dx^2}=-\frac{1}{x_1ln2}$
在定义域$0 \leq p_k \leq 1$, 始终有 $\frac{d^2(g(x_1))}{dx^2}=-\frac{1}{x_1ln2} \leq 0$,所以最小值在边界处$x_1=0 或 x_1=1$取得:$min g(x_1)=0$
由推理可得$f(0,0,0,0,1,...,0)=0$
所以:
$0 \leq Ent(D) \leq log_{2}\mid y \mid$
信息增益
假定离散属性有V个可能的取值 {${a^1,a^2,...,a^V}$}, 如果使用特征a来对数据集D进行划分,则会产生V个分支结点,其中第 $v$ 个结点包含了数据集D中所有在特征a上取值为 $a^V$ 的样本总数,记为 $D^v$, 特征对样本集D进行划分的“样本增益”为:
$Gain(D,a)=Ent(D)-\sum_{v=1}^V \frac{\mid D^V \mid}{\mid D \mid}Ent(C^v)$
缺点
1.ID3没有考虑连续特征
2.ID3采用信息增益大的特征优先建立决策树的节点,取值比较多的特征比取值少的特征信息增益大
3.ID3算法对于缺失值的情况没有做考虑
4.没有考虑过拟合的情况
C4.5算法
增益率:
弥补ID3偏向于取值较多属性,C4.5算法不直接使用信息增益,而是使用一种叫增益率的方法来选择最优属性进行划分:
$Gain-ration(D,a)=\frac{Gain(D,a)}{IV(a)}$
$IV(a)$ 是属性 $a$ 的固有值:
$IV(a)=-\sum_{v=1}^V \frac{\mid D^v \mid}{\mid D \mid}log_2 \frac{\mid D^v \mid}{D}$
属性越多,熵越大,对分支过多的情况进行惩罚。
缺点
1.C4.5生成的是多叉树,生成决策树的效率比较慢
2.C4.5只能用于分类
3.C4.5由于使用了熵模型,对数运算耗时。
CART
Gini值:
度量数据集的纯度,Gini(D)反应了从数据集中随机抽取两个样本,类别标记不一致的概率,数据越小,纯度越高。
$Gini(D)=\sum_{k=1}^{\mid y \mid}\sum_{k' \neq k}p_kp_{k'}=1-\sum_{k=1}^{\mid y \mid}p_k^2$
$Gini-index(D,a)=\sum_{v=1}^V \frac{\mid D^v \mid}{\mid D \mid}Gini(D^v)$
剪枝
减指是决策树学习算法处理过拟合的重要手段。决策树剪枝的基本策略有“预剪枝”和“后剪枝”。预剪枝是对每个节点在划分前进行估计,若不能带来泛化能力的提升,则停止划分并将该节点标记为叶节点。后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上计算泛化能力是否提升,否则标记为叶节点。
预剪枝
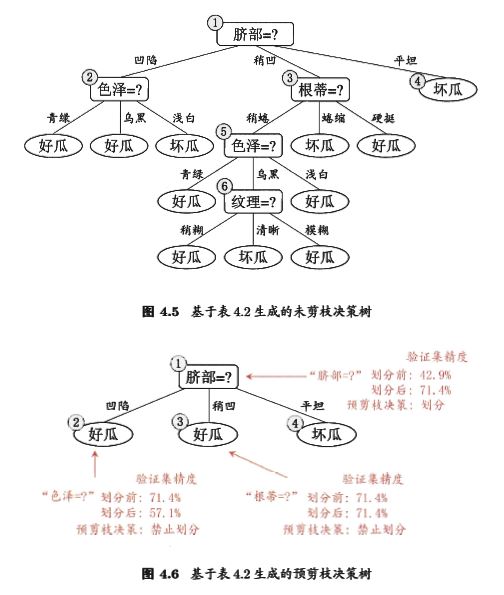

后剪枝
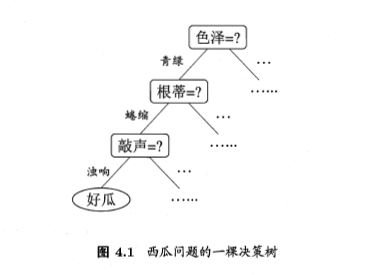
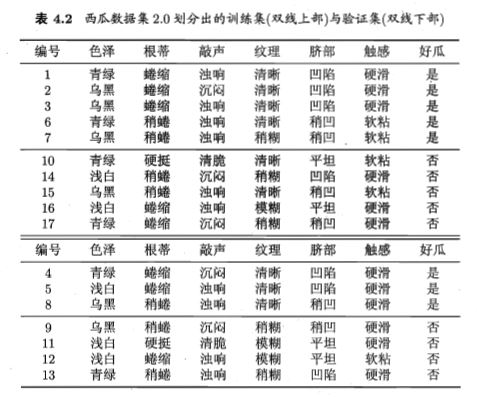
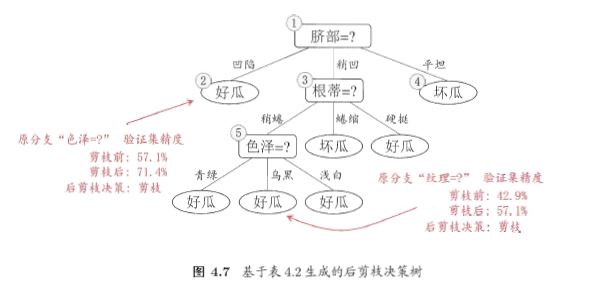
后剪枝先从训练集生成一棵完整的决策树如图4.5,该决策树的验证集精度为42.9%,后剪枝首先考察节点6,然后节点五,节点二,节点三,节点一,计算过程如图。
对比
- 后剪枝比预剪枝保留了更多的分支。
- 后剪枝欠拟合风险小,泛化能力优于预剪枝决策树
- 后剪枝是在生成决策树后进行的,自底向上对非叶节点逐个考察,训练时间与开销都比预剪枝大得多
连续与缺失值
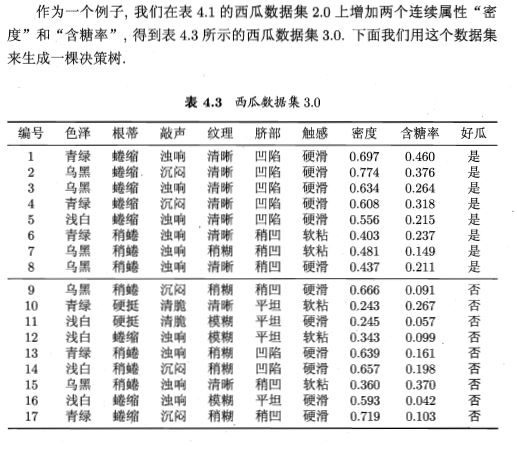
连续值处理:在决策树学习中使用连续属性进行决策
方法:连续属性离散化:(eg,二分法)
给定样本集$D$ 和连续属性,划分点$t$可以将D分为子集 $D_t^-$ 与 $D_t^+$, $D_t^-$包含在属性 $a$ 上不大于 $t$ 的样本,候选划分集合:
$T_a={\frac{a^i+a^{i+1}}{2} \mid 1 \leq i \leq n-1}$
然后我们可以像离散属性一样来选择划分点:
$Gain(D,a)=max_{t \in T_a}Gain(D,a,t)=max_{t \in T_a}Ent(D)-\sum_{\lambda \in {-,+}}\frac{\mid D_t^{\lambda} \mid}{\mid D \mid}Ent(D_t^{\lambda})$

缺失值处理
样本的某些属性值缺失如何进行划分属性的选择呢?
给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?