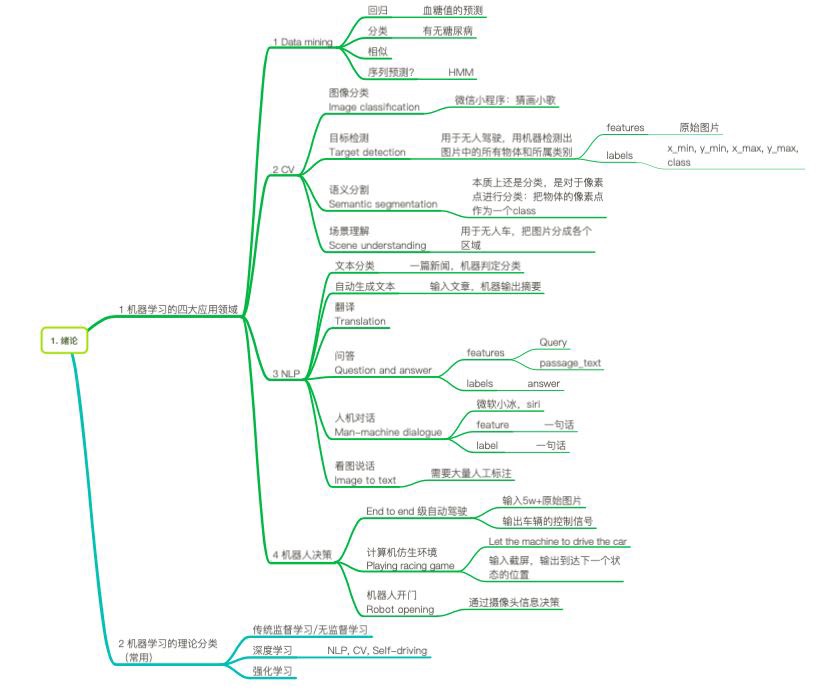
绪论
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。经验即数据。
机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型”的算法,learning algorithms.再用模型来预测未来数据。
术语
记录:
数据集:记录的集合
训练:从数据中学习模型的过程
训练集:训练过程中使用的数据样本的集合
分类任务:预测的结果为离散值(好瓜,坏瓜)
回归任务:预测值是连续值
根据训练数据是否有label,学习任务可划分为:“监督学习”,“无监督学习”
泛化能力:学得模型适用于新样本的能力
归纳演绎
归纳:从特殊到一般(机器学习)
演绎:从一般到特殊
发展历程
机器学习是人工智能研究发展到一定阶段的必然产物。
| 年代 | 事件 | 代表工作 |
|---|---|---|
| 二十世纪而五十年代到七十年代 | 人工智能的推理期 | 感知机、Adaline |
| 五十年代中后期 | 符号主义蓬勃发展,决策理论。增强学习 | 结构学习系统,概念学习系统 |
| 八十年代 | 决策树学习 | 由于复杂度过高而陷入低潮 |
| 九十年代 | 基于神将网络的连接学习 | hopfield,BP,产生黑箱模型 |
| 九十年代中期 | 统计学习 | SVM, 核方法 |
| 二十一世纪初 | 深度学习 | 对数据,硬件要求高 |
应用现状
今天,在计算机学科的诸多分支学科中,无论是多媒体,图形学,还是网络通信,软件工程,体系结构,芯片设计都能找到机器学习的身影,尤其是CV与NLP。
交叉学科:生物信息学
大数据时代的三大技术:机器学习,云计算,众包
数据挖掘与机器学习的关系:
数据挖掘技术在二十世纪九十年代形成,受数据库,机器学习,统计学影响最大。数据挖掘是从海量知识中发掘知识,这就必然涉及对海量数据的管理分析。数据库领域的研究为数据挖掘提供数据管理技术,而机器学习和统计学研究为数据挖掘提供数据分析技术,统计学主要是通过机器学习对数据挖掘发挥影响,机器学习领域与数据库领域是数据挖掘的两大支撑。