train loss与test loss结果分析
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
Loss和神经网络训练
训练前的检查工作
1.loss:在用很小的随机数初始化神经网络后,第一遍计算loss可以做一次检查(当然要记得把正则化系数设为0)。
2.接着把正则化系数设为正常的小值,加回正则化项,这时候再算损失/loss,应该比刚才要大一些。
3.试着去拟合一个小的数据集。最后一步,也是很重要的一步,在对大数据集做训练之前,先训练一个小的数据集,然后看看你的神经网络能够做到0损失/loss(当然,是指的正则化系数为0的情况下),因为如果神经网络实现是正确的,在无正则化项的情况下,完全能够过拟合这一小部分的数据。
监控
开始训练之后,我们可以通过监控一些指标来了解训练的状态。我们还记得有一些参数是我们认为敲定的,比如学习率,比如正则化系数。
1.损失/loss随每轮完整迭代后的变化
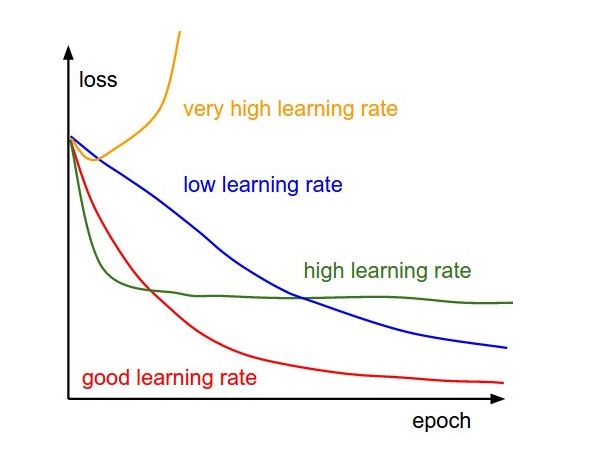
合适的学习率可以保证每轮完整训练之后,loss都减小,且能在一段时间后降到一个较小的程度。太小的学习率下loss减小的速度很慢,如果太激进,设置太高的学习率,开始的loss减小速度非常可观,可是到了某个程度之后就不再下降了,在离最低点一段距离的地方反复,无法下降了。
2.训练集/验证集上的准确度:判断分类器所处的拟合状态。
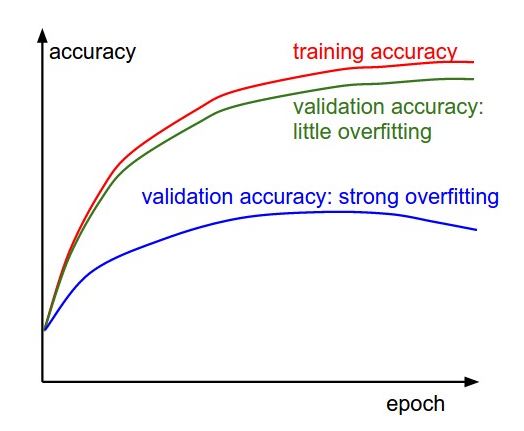
随着时间推进,训练集和验证集上的准确度都会上升,如果训练集上的准确度到达一定程度后,两者之间的差值比较大,那就要注意一下,可能是过拟合现象,如果差值不大,那说明模型状况良好。
3.权重:权重更新幅度和当前权重幅度的比值 权重更新部分是梯度和学习率的乘积,可以独立的检查这个比例,一个合适的比例大概是1e-3。如果得到的比例比这个值小很多,那么说明学习率设定太低了,反之则是设定太高了。
4.每一层的 激励/梯度值 分布: 如果参数初始化不正确,那整个训练过程会越来越慢,甚至直接停掉。
关于参数更新部分的注意点
当确信解析梯度实现正确后,那就该在后向传播算法中使用它更新权重参数了。就单参数更新这个部分,也是有讲究的:
1.拿到梯度之后,乘以设定的学习率,用现有的权重减去这个部分,得到新的权重参数(因为梯度表示变化率最大的增大方向,减去这个值之后,损失函数值才会下降)。
2.在实际训练过程中,随着训练过程推进,逐渐衰减学习率是很有必要的。我们继续回到下山的场景中,刚下山的时候,可能离最低点很远,那我步子迈大一点也没什么关系,可是快到山脚了,我还激进地大步飞奔,一不小心可能就迈过去了。所以还不如随着下山过程推进,逐步减缓一点点步伐。不过这个『火候』确实要好好把握,衰减太慢的话,最低段震荡的情况依旧;衰减太快的话,整个系统下降的『动力』衰减太快,很快就下降不动了。下面提一些常见的学习率衰减方式:
- 步伐衰减:这是很常见的一个衰减模式,每过一轮完整的训练周期(所有的图片都过了一遍)之后,学习率下降一些。比如比较常见的一个衰减率可能是每20轮完整训练周期,下降10%。不过最合适的值还真是依问题不同有变化。如果你在训练过程中,发现交叉验证集上呈现很高的错误率,还一直不下降,你可能就可以考虑考虑调整一下(衰减)学习率了。
- 指数级别衰减:需要自己敲定的超参数,是迭代轮数。
- 1/t衰减:有着数学形式为的衰减模式,其中是需要自己敲定的超参数,是迭代轮数。
超参数的设定与优化
神经网络的训练过程中,不可避免地要和很多超参数打交道,需要手动设定,大致包括:
1.初始学习率 2.学习率衰减程度 3.正则化系数/强度(包括l2正则化强度,dropout比例)
对于大的深层次神经网络而言,我们需要很多的时间去训练。因此在此之前我们花一些时间去做超参数搜索,以确定最佳设定是非常有必要的。最直接的方式就是在框架实现的过程中,设计一个会持续变换超参数实施优化,并记录每个超参数下每一轮完整训练迭代下的验证集状态和效果。实际工程中,神经网络里确定这些超参数,我们一般很少使用n折交叉验证,一般使用一份固定的交叉验证集就可以了。
一般对超参数的尝试和搜索都是在log域进行的。例如,一个典型的学习率搜索序列就是learning_rate = 10 ** uniform(-6, 1)。我们先生成均匀分布的序列,再以10为底做指数运算,其实我们在正则化系数中也做了一样的策略。比如常见的搜索序列为[0.5, 0.9, 0.95, 0.99]。另外还得注意一点,如果交叉验证取得的最佳超参数结果在分布边缘,要特别注意,也许取的均匀分布范围本身就是不合理的,也许扩充一下这个搜索范围会有更好的参数。
模型融合与优化:
实际工程中,一个能有效提高最后神经网络效果的方式是,训练出多个独立的模型,在预测阶段选结果中的众数。模型融合能在一定程度上缓解过拟合的现象,对最后的结果有一定帮助,我们有一些方式可以得到同一个问题的不同独立模型:
- 使用不同的初始化参数。先用交叉验证确定最佳的超参数,然后选取不同的初始值进行训练,结果模型能有一定程度的差别。
- 选取交叉验证排序靠前的模型。在用交叉验证确定超参数的时候,选取top的部分超参数,分别进行训练和建模。
- 选取训练过程中不同时间点的模型。神经网络训练确实是一件非常耗时的事情,因此有些人在模型训练到一定准确度之后,取不同的时间点的模型去做融合。不过比较明显的是,这样模型之间的差异性其实比较小,好处是一次训练也可以有模型融合的收益。
检查你的初始权重是否合理,在关掉正则化项的系统里,是否可以取得100%的准确度。
在训练过程中,对损失函数结果做记录,以及训练集和交叉验证集上的准确度。
最常见的权重更新方式是SGD+Momentum,推荐试试RMSProp自适应学习率更新算法。
随着时间推进要用不同的方式去衰减学习率。
用交叉验证等去搜索和找到最合适的超参数。
记得也做做模型融合的工作,对结果有帮助。
loss保持常数的采坑记录
1.loss等于87.33这个问题是在对Inception-V3网络不管是fine-tuning还是train的时候遇到的,无论网络迭代多少次,网络的loss一直保持恒定。
原因(溢出):
由于loss的最大值由FLT_MIN计算得到,FLT_MIN使其对应的自然对数正好是-87.3356,这也就对应上了loss保持87.3356了。这说明softmax在计算的过程中得到了概率值出现了零,由于softmax是用指数函数计算的,指数函数的值都是大于0的,所以应该是计算过程中出现了float溢出的异常,也就是出现了inf,nan等异常值导致softmax输出为0.当softmax之前的feature值过大时,由于softmax先求指数,会超出float的数据范围,成为inf。inf与其他任何数值的和都是inf,softmax在做除法时任何正常范围的数值除以inf都会变成0.然后求loss就出现了87.3356的情况。
solution:
由于softmax输入的feature由两部分计算得到:一部分是输入数据,另一部分是各层的权值等组成:
(1).减小初始化权重,以使得softmax的输入feature处于一个比较小的范围
(2).降低学习率,这样可以减小权重的波动范围
(3).如果有BN(batch normalization)层,finetune时最好不要冻结BN的参数,否则数据分布不一致时很容易使输出值变得很大(注意将batch_norm_param中的use_global_stats设置为false )。
(4).观察数据中是否有异常样本或异常label导致数据读取异常
loss不下降的常见原因
1)数据的输入是否正常,data和label是否一致。
2)网络架构的选择,一般是越深越好,也分数据集。 并且用不用在大数据集上pre-train的参数也很重要的。
3)loss 对不对。