自从2014年Ian Goodfellow提出以来,GAN就存在着训练困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。从那时起,很多论文都在尝试解决,但是效果不尽人意,比如最有名的一个改进DCGAN依靠的是对判别器和生成器的架构进行实验枚举,最终找到一组比较好的网络架构设置,但是实际上是治标不治本,没有彻底解决问题。而今天的主角Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
推荐阅读:《Towards Principled Methods for Training Generative Adversarial Networks》,《Wasserstein GAN》
而改进后相比原始GAN的算法实现流程却只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
1.原始GAN有什么问题
原始GAN中:
对于D,需要最小化如下损失函数,尽可能把真实样本分为正例,生成样本分为负例:
 (1)
(1)
对于G,Goodfellow一开始提出来一个损失函数,后来又提出了一个改进的损失函数,分别是
$E_{x\sim P_g}[log(1-D(x))]$ (2)
$E_{x\sim P_g}[-log(D(x))]$ (3)
《Towards Principled Methods for Training Generative Adversarial Networks》分别分析了这两种形式的原始GAN各自的问题所在,下面分别说明。
第一种原始GAN形式的问题
一句话概括:判别器越好,生成器梯度消失越严重。WGAN前作从两个角度进行了论证,第一个角度是从生成器的等价损失函数切入的。
首先,从Eq.(1)可以知道,固定G,最优的D是 $D^*(x)=\frac{p_r(x)}{p_r(x)+p_g(x)}$ Eq.(4) 这个结果就是公式1的最优值,求导而得,就是看一个样本x来自真实分布和生成分布的可能性的相对比例。如果 $p_r(x)=0$且$p_g(x) \neq 0$, 最优判别器就应该非常自信地给出概率0;如果$p_r(x)=p_g(x)$, 说明该样本是真是假的可能性刚好一半一半,此时最优判别器也应该给出概率0.5。
然而GAN训练有一个trick,就是别把判别器训练得太好,否则在实验中生成器会完全学不动(loss降不下去),为了探究背后的原因,我们就可以看看在极端情况——判别器最优时,生成器的损失函数变成什么。给公式2加上一个不依赖于生成器的项,使之变成:
$E_{x\sim P_r}[logD(x)]+E_{x\sim P_g}[log(1-D(x))]$
注意,最小化这个损失函数等价于最小化公式2,而且它刚好是判别器损失函数的反。代入最优判别器即公式4,再进行简单的变换可以得到:
$E_{x\sim P_r}[log\frac{p_r(x)}{\frac{1}{2}[p_r(x)+p_g(x)]}]+E_{x\sim P_g}[log\frac{p_g(x)}{\frac{1}{2}[p_r(x)+p_g(x)]}]-2log2$ =$2JS(P_r||P_g)-2log2$. Eq.(5)
变换成这个样子是为了引入Kullback–Leibler divergence(简称KL散度)和Jensen-Shannon divergence(简称JS散度)这两个重要的相似度衡量指标,后面的主角之一Wasserstein距离,就是要来吊打它们两个的。所以接下来介绍这两个重要的配角——KL散度和JS散度:
$KL(P_1\mid \mid P_2)=E_{x\sim P_1}log\frac{P_1}{P_2}$. Eq.(6)
$JS(P1\mid \mid P2)=\frac{1}{2}KL(P_1\mid \mid \frac{P_1+P_2}{2})+\frac{1}{2}KL(P_2\mid \mid \frac{P_1+P_2}{2})$. Eq.(7)
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布P_r与生成分布P_g之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化$P_r$和$P_g$之间的JS散度。
问题就出在这个JS散度上。我们会希望如果两个分布之间越接近,它们的JS散度越小,我们通过优化JS散度就能将$P_g$“拉向”$P_r$,最终以假乱真。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略(下面解释什么叫可忽略),它们的JS散度是多少呢?
答案是$log2$,因为对于任意$x$, 只有如下四种可能性:
$P_1(x)=0$且$P_2(x)=0$
$P_1(x)\neq0$且$P_2(x)\neq0$
$P_1(x)=0$且$P_2(x)\neq0$
$P_1(x)\neq0$且$P_2(x)=0$
第一种对计算JS散度无贡献,第二种情况由于重叠部分可忽略所以贡献也为0,第三种情况对公式7右边第一个项的贡献是$log\frac{P_2}{\frac{1}{2}(P_2+0)}=log2$,第四种情况与之类似,所以最终$JS(P_1\mid \mid P_2)=log2$
换句话说,无论$P_r$跟$P_g$ 是远在天边,还是近在眼前,只要它们俩没有一点重叠或者重叠部分可忽略,JS散度就固定是常数$log 2$,而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。
那么$P_r$与$P_g$不重叠或重叠部分可忽略的可能性有多大?不严谨的答案是:非常大。比较严谨的答案是:当$P_r$与$P_g$的支撑集(support)是高维空间中的低维流形(manifold)时,$P_r$与$P_g$重叠部分测度(measure)为0的概率为1。
- 支撑集(support)其实就是函数的非零部分子集,比如ReLU函数的支撑集就是(0, +\infty),一个概率分布的支撑集就是所有概率密度非零部分的集合。
- 流形(manifold)是高维空间中曲线、曲面概念的拓广,我们可以在低维上直观理解这个概念,比如我们说三维空间中的一个曲面是一个二维流形,因为它的本质维度(intrinsic dimension)只有2,一个点在这个二维流形上移动只有两个方向的自由度。同理,三维空间或者二维空间中的一条曲线都是一个一维流形。
- 测度(measure)是高维空间中长度、面积、体积概念的拓广,可以理解为“超体积”。
回过头来看第一句话,“当$P_r$与$P_g$的支撑集是高维空间中的低维流形时”,基本上是成立的。原因是GAN中的生成器一般是从某个低维(比如100维)的随机分布中采样出一个编码向量,再经过一个神经网络生成出一个高维样本(比如64x64的图片就有4096维)。当生成器的参数固定时,生成样本的概率分布虽然是定义在4096维的空间上,但它本身所有可能产生的变化已经被那个100维的随机分布限定了,其本质维度就是100,再考虑到神经网络带来的映射降维,最终可能比100还小,所以生成样本分布的支撑集就在4096维空间中构成一个最多100维的低维流形,“撑不满”整个高维空间。
“撑不满”就会导致真实分布与生成分布难以“碰到面”,这很容易在二维空间中理解:一方面,二维平面中随机取两条曲线,它们之间刚好存在重叠线段的概率为0;另一方面,虽然它们很大可能会存在交叉点,但是相比于两条曲线而言,交叉点比曲线低一个维度,长度(测度)为0,可忽略。三维空间中也是类似的,随机取两个曲面,它们之间最多就是比较有可能存在交叉线,但是交叉线比曲面低一个维度,面积(测度)是0,可忽略。从低维空间拓展到高维空间,就有了如下逻辑:因为一开始生成器随机初始化,所以$P_g$几乎不可能与$P_r$有什么关联,所以它们的支撑集之间的重叠部分要么不存在,要么就比$P_r$和$P_g$的最小维度还要低至少一个维度,故而测度为0。所谓“重叠部分测度为0”,就是上文所言“不重叠或者重叠部分可忽略”的意思。
我们就得到了WGAN前作中关于生成器梯度消失的第一个论证:在(近似)最优判别器下,最小化生成器的loss等价于最小化$P_r$与$P_g$之间的JS散度,而由于$P_r$与$P_g$几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数$log 2$,最终导致生成器的梯度(近似)为0,梯度消失。
从第二个角度论证梯度消失
- 首先,P_r与P_g之间几乎不可能有不可忽略的重叠,所以无论它们之间的“缝隙”多狭小,都肯定存在一个最优分割曲面把它们隔开,最多就是在那些可忽略的重叠处隔不开而已。
- 由于判别器作为一个神经网络可以无限拟合这个分隔曲面,所以存在一个最优判别器,对几乎所有真实样本给出概率1,对几乎所有生成样本给出概率0,而那些隔不开的部分就是难以被最优判别器分类的样本,但是它们的测度为0,可忽略。
- 最优判别器在真实分布和生成分布的支撑集上给出的概率都是常数(1和0),导致生成器的loss梯度为0,梯度消失。
有了这些理论分析,原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
第二种原始GAN形式的问题
一句话概括:最小化第二种生成器loss函数,会等价于最小化一个不合理的距离衡量,导致两个问题,一是梯度不稳定,二是collapse mode即多样性不足。《Towards Principled Methods for Training Generative Adversarial Networks》又是从两个角度进行了论证,下面只说第一个角度.
上文提到固定G,最优的D是$D^(x)=\frac{p_r(x)}{p_r(x)+p_g(x)}$, 这里,我们可以把KL散度变化成含$D^$的模式:
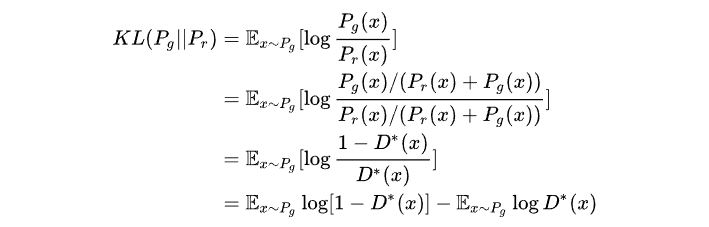
由以上公式可知:
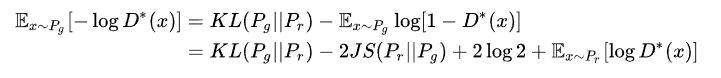
注意上式最后两项不依赖于生成器G,最终得到最小化公式3等价于最小化
$KL(P_g\mid \mid P_r)-2JS(P_r\mid \mid P_g)$ Eq.(11)
这个等价最小化目标存在两个严重的问题。
第一是它同时要最小化生成分布与真实分布的KL散度,却又要最大化两者的JS散度,一个要拉近,一个却要推远!这在直观上非常荒谬,在数值上则会导致梯度不稳定,这是后面那个JS散度项的毛病。
第二,即便是前面那个正常的KL散度项也有毛病。因为KL散度不是一个对称的衡量,$KL(P_g\mid \mid P_r)$ 与 $KL(P_r\mid \mid P_g)$ 是有差别的。以前者为例:
- 当$P_g(x)\rightarrow0$而$P_r(x)\rightarrow1$时,$P_g(x)log\frac{P_g(x)}{P_r(x)}\rightarrow0$, 对$KL(P_g \mid \mid P_r)$的贡献趋于0.
- 当$P_g(x)\rightarrow1$而$P_r(x)\rightarrow0$时,$P_g(x)log\frac{P_g(x)}{P_r(x)}\rightarrow+\infty$, 对$KL(P_g \mid \mid P_r)$的贡献趋于无穷大.
换言之,$KL(P_g \mid \mid P_r)$ 对于上面两种错误的惩罚是不一样的,第一种错误对应的是“生成器没能生成真实的样本”,惩罚微小;第二种错误对应的是“生成器生成了不真实的样本” ,惩罚巨大。第一种错误对应的是缺乏多样性,第二种错误对应的是缺乏准确性。这一放一打之下,生成器宁可多生成一些重复但是很“安全”的样本,也不愿意去生成多样性的样本,因为那样一不小心就会产生第二种错误,得不偿失。这种现象就是大家常说的collapse mode。
第一部分小结:在原始GAN的(近似)最优判别器下,第一种生成器loss面临梯度消失问题,第二种生成器loss面临优化目标荒谬、梯度不稳定、对多样性与准确性惩罚不平衡导致mode collapse这几个问题。
关于实验证明,可以参考paper原文
2.WGAN之前的一个过渡解决方案
原始GAN问题的根源可以归结为两点,一是等价优化的距离衡量(KL散度、JS散度)不合理,二是生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
WGAN前作其实已经针对第二点提出了一个解决方案,就是对生成样本和真实样本加噪声,直观上说,使得原本的两个低维流形“弥散”到整个高维空间,强行让它们产生不可忽略的重叠。而一旦存在重叠,JS散度就能真正发挥作用,此时如果两个分布越靠近,它们“弥散”出来的部分重叠得越多,JS散度也会越小而不会一直是一个常数,于是(在第一种原始GAN形式下)梯度消失的问题就解决了。在训练过程中,我们可以对所加的噪声进行退火(annealing),慢慢减小其方差,到后面两个低维流形“本体”都已经有重叠时,就算把噪声完全拿掉,JS散度也能照样发挥作用,继续产生有意义的梯度把两个低维流形拉近,直到它们接近完全重合。以上是对原文的直观解释。
在这个解决方案下我们可以放心地把判别器训练到接近最优,不必担心梯度消失的问题。而当判别器最优时,对公式9取反可得判别器的最小loss为:
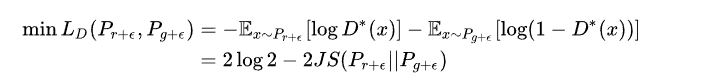
其中$P_{r+\epsilon},P_{g+\epsilon}$ 分别是加噪声后的真实分布与生成分布。反过来说,从最优判别器的loss可以反推出当前两个加噪分布的JS散度。两个加噪分布的JS散度可以在某种程度上代表两个原本分布的距离,也就是说可以通过最优判别器的loss反映训练进程!
但是,因为加噪JS散度的具体数值受到噪声的方差影响,随着噪声的退火,前后的数值就没法比较了,所以它不能成为$P_r$和$P_g$距离的本质性衡量。加噪方案是针对原始GAN问题的第二点根源提出的,解决了训练不稳定的问题,不需要小心平衡判别器训练的火候,可以放心地把判别器训练到接近最优,但是仍然没能够提供一个衡量训练进程的数值指标。但是WGAN本作就从第一点根源出发,用Wasserstein距离代替JS散度,同时完成了稳定训练和进程指标的问题!
3.Wasserstein距离的优越性质
Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:
$W(P_r,P_g)=\mathop{inf}\limits_{r\sim \prod(P_r,P_g)}E_{(x,y)\sim\gamma}[\mid \mid x-y\mid \mid ]$ Eq.(12)
解释说明:$\prod(P_r,P_g)$ 是$P_r$,$P_g$组合起来的所有可能的联合分布的集合,反过来讲,$\prod(P_r,P_g)$ 中每一个分布的边缘分布都是 $P_r$ 和$P_g$. 对于每一个可能的联合分布 $\gamma$ 而言,可以从中采样 $(x,y)\sim \gamma$ 得到一个真实样本 $x$ 和一个生成样本 $y$ , 并算出这对样本的距离 $\mid \mid x-y\mid \mid$, 所以可以计算该联合分布 $\gamma$ 下样本对距离的期望值 $\mathbb{E}_{(x, y) \sim \gamma} [\mid \mid x - y\mid \mid]$ 。在所有可能的联合分布中能够对这个期望值取到的下界 $W(P_r,P_g)$ ,就定义为Wasserstein距离。
直观上可以把 $\mathbb{E}_{(x, y) \sim \gamma} [\mid \mid x - y\mid \mid]$ 理解为在 $\gamma$ 这个“路径规划”下把 $P_r$ 这堆“沙土”挪到 $P_g$ “位置”所需的“消耗”,而 $W(P_r, P_g)$ 就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。WGAN本作通过简单的例子展示了这一点。考虑如下二维空间中的两个分布 $P_1$ 和 $P_2$,$P_1$在线段AB上均匀分布, $P_2$ 在线段CD上均匀分布,通过控制参数 $\theta$ 可以控制着两个分布的距离远近。
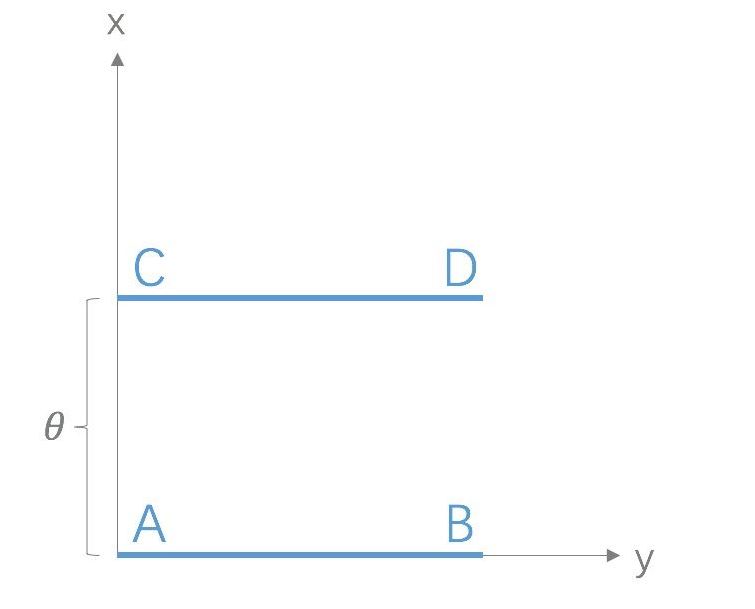
此时容易得到

KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化 $\theta$ 这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
4.从Wasserstein距离到WGAN
既然Wasserstein距离有如此优越的性质,如果我们能够把它定义为生成器的loss,不就可以产生有意义的梯度来更新生成器,使得生成分布被拉向真实分布吗?
没那么简单,因为Wasserstein距离定义(公式12)中的 $\inf_{\gamma \sim \Pi (P_r, P_g)}$ 没法直接求解,不过没关系,作者用了一个已有的定理把它变换为如下形式:
$W(P_r, P_g) = \frac{1}{K} \sup_{\mid \mid f\mid\mid_L \leq K} \mathbb{E}{x \sim P_r} [f(x)] - \mathbb{E}{x \sim P_g} [f(x)]$(公式13)
证明过程见paper附录。
首先需要介绍一个概念——Lipschitz连续。它其实就是在一个连续函数 $f$ 上面额外施加了一个限制,要求存在一个常数 $K\geq 0$ 使得定义域内的任意两个元素 $x_1$ 和 $x_2$ 都满足
$\mid f(x_1) - f(x_2)\mid \leq K \mid x_1 - x_2\mid$
此时称函数 $f$ 的Lipschitz常数为K。
简单理解,比如说 $f$ 的定义域是实数集合,那上面的要求就等价于 $f$ 的导函数绝对值不超过K。再比如说 $\log (x)$ 就不是Lipschitz连续,因为它的导函数没有上界。Lipschitz连续条件限制了一个连续函数的最大局部变动幅度。
公式13的意思就是在要求函数f的Lipschitz常数 $\mid \mid f\mid \mid_L$ 不超过K的条件下,对所有可能满足条件的 $f$ 取到 $\mathbb{E}{x \sim P_r} [f(x)] - \mathbb{E}{x \sim P_g} [f(x)]$ 的上界,然后再除以 $K$。特别地,我们可以用一组参数w来定义一系列可能的函数 $f_w$,此时求解公式13可以近似变成求解如下形式
$K \cdot W(P_r, P_g) \approx \max_{w: \mid f_w\mid_L \leq K} \mathbb{E}{x \sim P_r} [f_w(x)] - \mathbb{E}{x \sim P_g} [f_w(x)]$(公式14)
由于神经网络的拟合能力足够强大,我们有理由相信,这样定义出来的一系列 $f_w$ 虽然无法囊括所有可能,但是也足以高度近似公式13要求的那个 $sup_{\mid \mid f\mid \mid_L \leq K}$ 了。
最后,还不能忘了满足公式14中 $\mid \mid f_w\mid \mid_L \leq K$ 这个限制。我们其实不关心具体的K是多少,只要它不是正无穷就行,因为它只是会使得梯度变大K倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络 $f_\theta$ 的所有参数 $w_i$ 的不超过某个范围 $[-c, c]$,比如 $w_i \in [- 0.01, 0.01]$,此时关于输入样本x的导数 $\frac{\partial f_w}{\partial x}$ 也不会超过某个范围,所以一定存在某个不知道的常数K使得 $f_w$ 的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完w后把它clip回这个范围就可以了。
到此为止,我们可以构造一个含参数w、最后一层不是非线性激活层的判别器网络 $f_w$ ,在限制w不超过某个范围的条件下,使得
$L = \mathbb{E}{x \sim P_r} [f_w(x)] - \mathbb{E}{x \sim P_g} [f_w(x)]$ (公式15)
尽可能取到最大,此时L就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数K)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器 $f_w$ 做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化L,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到L的第一项与生成器无关,就得到了WGAN的两个loss。
$- \mathbb{E}_{x \sim P_g} [f_w(x)]$(公式16,WGAN生成器loss函数)
$\mathbb{E}{x \sim P_g} [f_w(x)]- \mathbb{E}{x \sim P_r} [f_w(x)]$(公式17,WGAN判别器loss函数)
公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。

上文说过,WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
前三点都是从理论分析中得到的,已经介绍完毕;第四点却是作者从实验中发现的,属于trick,相对比较“玄”。作者发现如果使用Adam,判别器的loss有时候会崩掉,当它崩掉时,Adam给出的更新方向与梯度方向夹角的cos值就变成负数,更新方向与梯度方向南辕北辙,这意味着判别器的loss梯度是不稳定的,所以不适合用Adam这类基于动量的优化算法。作者改用RMSProp之后,问题就解决了,因为RMSProp适合梯度不稳定的情况。
实验验证:
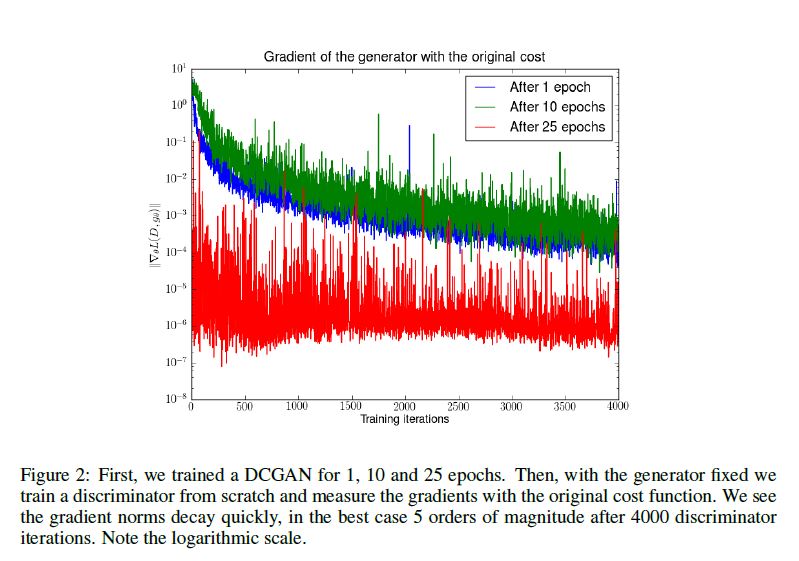
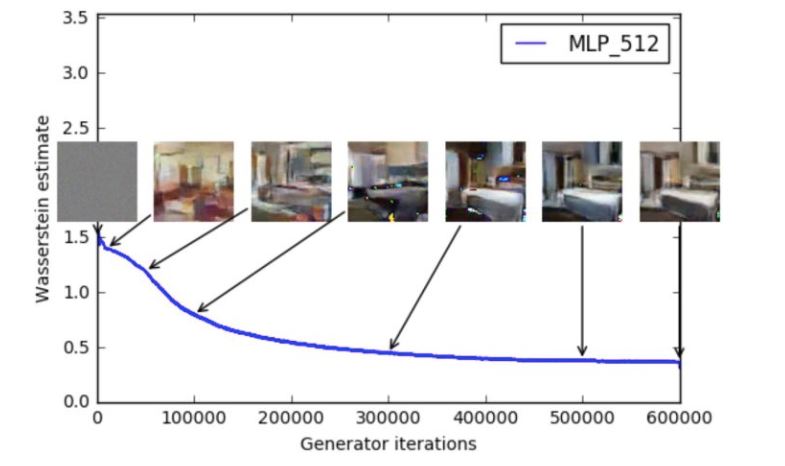
1.判别器所近似的Wasserstein距离与生成器的生成图片质量高度相关,如下所示(此即题图):
2.WGAN如果用类似DCGAN架构,生成图片的效果与DCGAN差不多:

但是厉害的地方在于WGAN不用DCGAN各种特殊的架构设计也能做到不错的效果,比如如果大家一起拿掉Batch Normalization的话,DCGAN就崩了:

如果WGAN和原始GAN都使用多层全连接网络(MLP),不用CNN,WGAN质量会变差些,但是原始GAN不仅质量变得更差,而且还出现了collapse mode,即多样性不足:

3.在所有WGAN的实验中未观察到collapse mode。
相比于判别器迭代次数的改变,对判别器架构超参的改变会直接影响到对应的Lipschitz常数K,进而改变近似Wasserstein距离的倍数,前后两轮训练的指标就肯定不能比较了,这是需要在实际应用中注意的。对此我想到了一个工程化的解决方式,不是很优雅:取同样一对生成分布和真实分布,让前后两个不同架构的判别器各自拟合到收敛,看收敛到的指标差多少倍,可以近似认为是后面的K_2相对前面K_1的变化倍数,于是就可以用这个变化倍数校正前后两轮训练的指标。
总结
《Towards Principled Methods for Training Generative Adversarial Networks》分析了Ian Goodfellow提出的原始GAN两种形式各自的问题,第一种形式等价在最优判别器下等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;第二种形式在最优判别器下等价于既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致梯度不稳定,而且KL散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致collapse mode现象。
《Towards Principled Methods for Training Generative Adversarial Networks》针对分布重叠问题提出了一个过渡解决方案,通过对生成样本和真实样本加噪声使得两个分布产生重叠,理论上可以解决训练不稳定的问题,可以放心训练判别器到接近最优,但是未能提供一个指示训练进程的可靠指标,也未做实验验证。
WGAN引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成分布与真实分布。WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。作者对WGAN进行了实验验证。