概述
聚类(Clustering)的本质是对数据进行分类,将相异的数据尽可能地分开,而将相似的数据聚成一个类别(簇),使得同一类别的数据具有尽可能高的同质性(homogeneity),类别之间有尽可能高的异质性(heterogeneity),从而方便从数据中发现隐含的有用信息。聚类算法的应用包含如下几方面:
- 其他数据挖掘任务的关键中间环节:用于构建数据概要,用于分类、模式识别、假设生成和测试;用于异常检测,检测远离群簇的点。
- 数据摘要、数据压缩、数据降维:例如图像处理中的矢量量化技术。创建一个包含所有簇原型的表,即每个原型赋予一个整数值,作为它在表中的索引。每个对象用与它所在簇相关联的原型的索引表示。
- 协同过滤:用于推荐系统和用户细分。
- 动态趋势检测:对流数据进行聚类,检测动态趋势和模式。
- 用于多媒体数据、生物数据、社交网络数据的应用。
聚类算法的分类
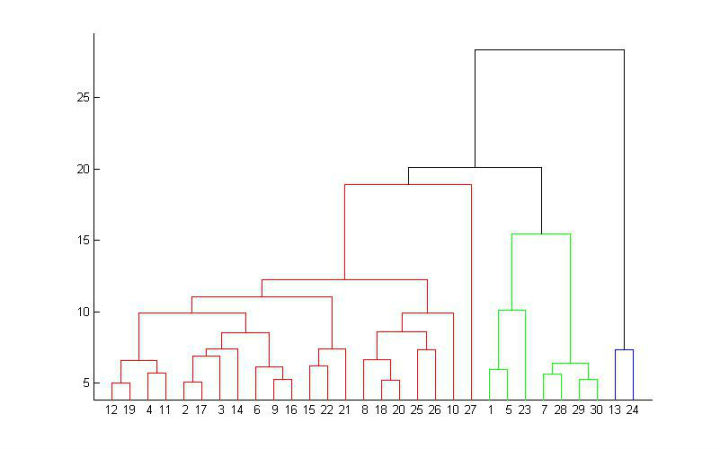
1.hierarchical methods:主要讲给定的数据集进行逐层分解,直到满足某种条件为止。具体可分为“自底向上”和“自顶向下”两种方案。在“自底向上”方案中,初始时每个数据点组成一个单独的组,在接下来的迭代中,按一定的距离度量将相互邻近的组合并成一个组,直至所有的记录组成一个分组或者满足某个条件为止。代表算法有:,
,CHAMELEON等。自底向上的凝聚层次聚类如下图所示。