from 《Generative Adversarial Nets》 NIPS 2014 by Goodfellow.
1.GAN的基本思想
GAN通过博弈的思想来训练生成模型与对狼模型,基本思想不再重复阐述,可用如下图替代。
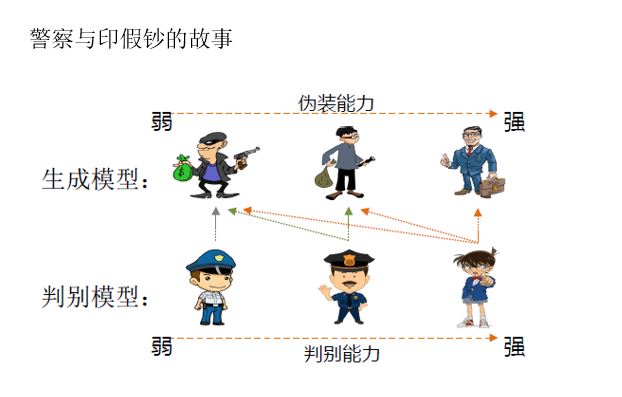
2.GAN的基本框架
在下面的示例图像中,蓝色区域显示了图像空间中包含真实图像的部分,具有很高的概率(超过某个阈值),黑点表示我们的数据点(每个点是数据集中的一个图像)。现在,生成模型描述分布 $\hat{p}_\theta(x)$ (绿色),它是通过从一个单位高斯分布(红色)中取点并通过一个(确定性)神经网络映射它们隐式定义的——我们的生成模型(黄色)。 我们的神经网络是含参数 $\theta$ 的函数, 调整这些参数将调整生成的采样分布。 我们的目标是生成一个分布(参数θ)匹配真实数据分布(例如,通过KL散度)。因此,你可以想象绿色分布随机,然后开始训练,迭代的改变参数使生成分布更接近真实分布。
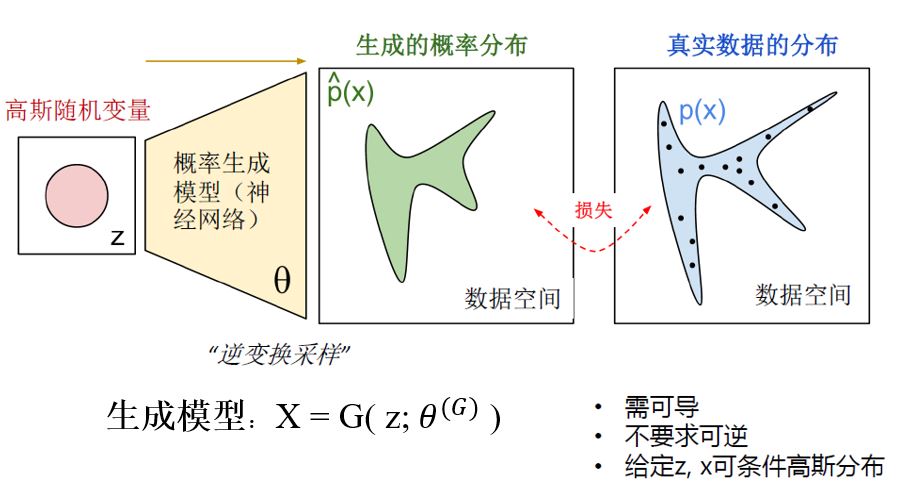
3.常用散度
散度是用来衡量两个分布之间差异的指标,因此,在讲解GAN原理之前,我要首先讲一下在GAN中用到的几个散度。 s
3.1.KL
KL散度又称relative entropy, 是信息论中的定义,是是两个概率分布P和Q差别的非对称性的度量。
维基百科中这样定义:
-
对于离散随机变量,概率分布P 和 Q的KL散度可按下式定义为:
$KL(P \mid \mid Q)= \sum_i P(i)log\frac{P(i)}{Q(i)}$.
即按概率P求得的P和Q的对数商的平均值。KL散度仅当概率P和Q各自总和均为1,且对于任何i皆满足 $Q(i)>0$及 $P(i)>0$ 时,才有定义。式中出现 $0log 0$ 的情况,其值按0处理。
-
对于连续随机变量,其概率分布P和Q可按积分方式定义为:
$KL(P \mid \mid Q)= E_{i\sim P}log\frac{P}{Q}$
即为P关于Q的相对熵。
特性
- 相对熵的值为非负数
- 当且仅当P=Q时,相对熵为0
- 尽管从直觉上KL散度是个度量或距离函数, 但是它实际上并不是一个真正的度量或距离。因为KL散度不具有对称性:从分布P到Q的距离通常并不等于从Q到P的距离。$KL(P\mid \mid Q)\neq KL(Q\mid \mid P)$, 这也是在距离度量中的一大忌。
3.2.JS
由于KL散度不具有对称性,用其衡量距离是行不通的,所以,在KL散度的基础上又出现了JS散度,JS散度既保留了KL散度的优点,又解决的对称问题:
$JS(P1\mid \mid P2)=\frac{1}{2}KL(P_1\mid \mid \frac{P_1+P_2}{2})+\frac{1}{2}KL(P_2\mid \mid \frac{P_1+P_2}{2})$
原始GAN是基于JS散度的度量,但经过实践与理论的分析,人们渐渐摒弃了这种度量方式,改用Wasserstein距离,关于原因参见我的另一篇博客《GAN'S problem》,这里只简要介绍Wasserstein距离的定义。
3.3.Wasserstein距离
Wasserstein距离又叫Earth-Mover距离(EM距离),用于衡量两个分布之间的距离,定义:
$W(P_r,P_g)=\mathop{inf}\limits_{r\sim \prod(P_r,P_g)}E_{(x,y)\sim\gamma}[\mid \mid x-y\mid \mid ]$
解释说明:$\prod(P_r,P_g)$ 是$P_r$,$P_g$组合起来的所有可能的联合分布的集合,反过来讲,$\prod(P_r,P_g)$ 中每一个分布的边缘分布都是 $P_r$ 和$P_g$. 对于每一个可能的联合分布 $\gamma$ 而言,可以从中采样 $(x,y)\sim \gamma$ 得到一个真实样本 $x$ 和一个生成样本 $y$ , 并算出这对样本的距离 $\mid \mid x-y\mid \mid$, 所以可以计算该联合分布 $\gamma$ 下样本对距离的期望值 $\mathbb{E}_{(x, y) \sim \gamma} [\mid \mid x - y\mid \mid]$ 。在所有可能的联合分布中能够对这个期望值取到的下界 $W(P_r,P_g)$ ,就定义为Wasserstein距离。
直观上可以把 $\mathbb{E}_{(x, y) \sim \gamma} [\mid \mid x - y\mid \mid]$ 理解为在 $\gamma$ 这个“路径规划”下把 $P_r$ 这堆“沙土”挪到 $P_g$ “位置”所需的“消耗”,而 $W(P_r, P_g)$ 就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。WGAN本作通过简单的例子展示了这一点。考虑如下二维空间中的两个分布 $P_1$ 和 $P_2$,$P_1$在线段AB上均匀分布, $P_2$ 在线段CD上均匀分布,通过控制参数 $\theta$ 可以控制着两个分布的距离远近。
4.GAN原理
GAN的思想启发自博弈论中的零和游戏,包含一个生成网络G和一个判别网络D。
4.1 目标函数:

4.2 workflow
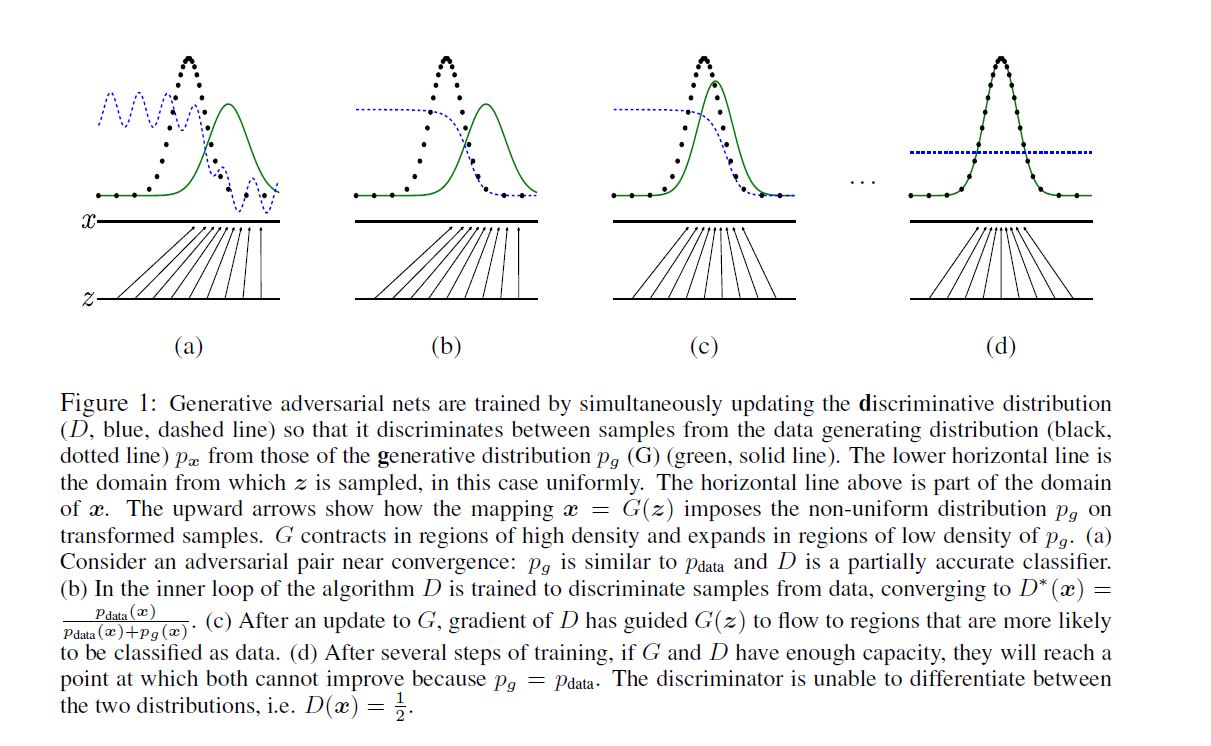
4.3 算法:

4.4 优化 $p_g=p_{data}$
1.首先固定G,优化D。 对D的目标函数求导,并验证最优解即最大值为:
$D_G^*(x)=\frac{p_{data}}{p_{data}(x)+p_{g}(x)}$
proof 如下:

因此目标函数可重写为:
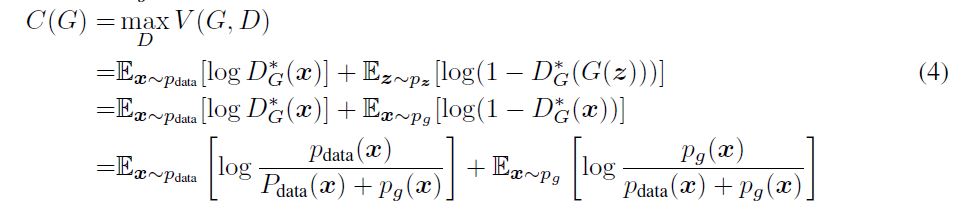
2.接下来固定D, 训练G,在G的全局最小值处,目标函数为$-log4$.
证明过程如下:

在当前最优的D下,G的目标函数为 $-log4+2*JS(p_{data}\mid \mid p_{g})$,由于两分布是非负的,所以G的全局最优解为-log4, 此时 $p_{data}=p_{g}$.
最后可以证明当且仅当$p_{data}=p_{g}$,
4.5 收敛性
原文中给出证明,如果G和D有足够的能力,那么给定G,D可以达到最优解, 并且$p_g$ 可以更新来优化目标函数,使得 $p_{g}$ 收敛于$p_{data}$.
证明过程:

GAN特性
优点:
- 计算梯度时只用到了反向传播,而不需要马尔科夫链。
- 训练时不需要对隐变量做推断。
- 理论上,只要是可微分函数都能用于构建D和G,因而能够与深度学习结合来学 习深度产生式网络(deep generative model)。
- 统计角度上来看,G的参数更新不是直接来自于数据样本,而是使用来自D的反传梯度。
缺点
- 生成器的分布没有显示的表达
- 比较难训练,D与G之间需要很好的同步,例如D更新k次而G更新1次。 将在后文中介绍GAN的缺点与训练技巧