预备知识
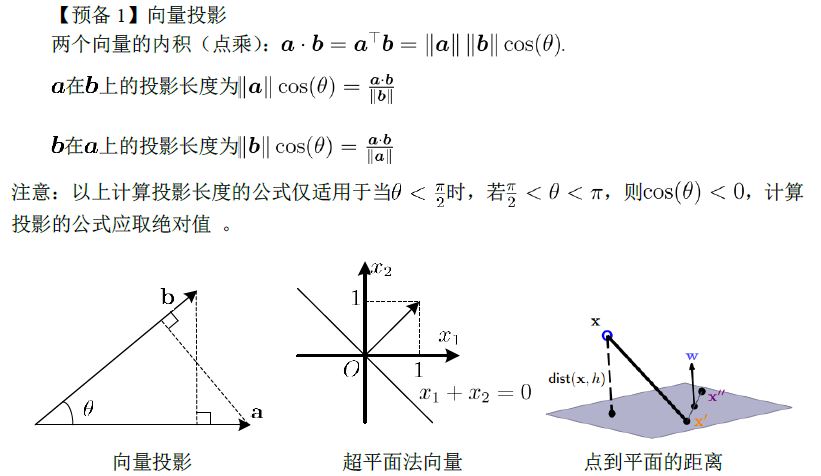

间隔与支持向量
分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。
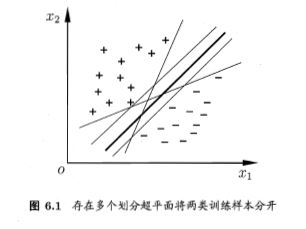
直观来说,应该找位于两类训练样本“正中间”的划分超平面,因为其对训练样本局部扰动的“容忍”性最好。
在训练样本中,划分超平面可以通过线性方程 $\mathbb{w}^T\mathbb{x}+b=0$ 来描述。其中 $\mathbb{w}=(w_1;w_2;...;d_d)$ 为法向量,决定了超平面的方向;b为位移,决定了超平面与原点之间的距离。样本空间中任意点 $x$ 到超平面$(\mathbb{w},b)$ 的距离可写为:
$r=\frac{\mid \mathbb{w}^T\mathbb{x}+b \mid}{\mid \mid \mathbb{w} \mid \mid}$.
证明:
任意取超平面上一个点 $x'$,则点 $x$ 到超平面的距离等于向量 $(x-x')$ 在法向量 $w$(参考预备2)的投影长度(参考预备1):
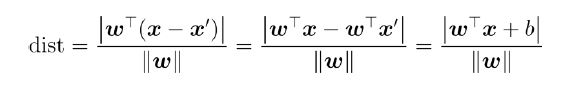 注意:上式推导过程中,分子之所有取绝对值是由于向量内积可能小于零;另外,由于 $x'$ 是超平上面的点,因此 $\mathbb{w}^T\mathbb{x'}+b=0$,即 $b=-\mathbb{w}^T\mathbb{x'}$。
注意:上式推导过程中,分子之所有取绝对值是由于向量内积可能小于零;另外,由于 $x'$ 是超平上面的点,因此 $\mathbb{w}^T\mathbb{x'}+b=0$,即 $b=-\mathbb{w}^T\mathbb{x'}$。

注意到,距离超平面最近的训练样本可以使上式的等号成立,由6.2知这些训练样本到超平面的距离为:
$dist=\frac{\mid \mathbb{w}^T\mathbb{x}+b \mid}{\mid \mid \mathbb{w} \mid \mid}=\frac{1}{\mid \mid w \mid \mid}$.
那么很容易知道,两个异类支持向量到超平面的距离之和是 $\frac{2}{\mid \mid w \mid \mid}$
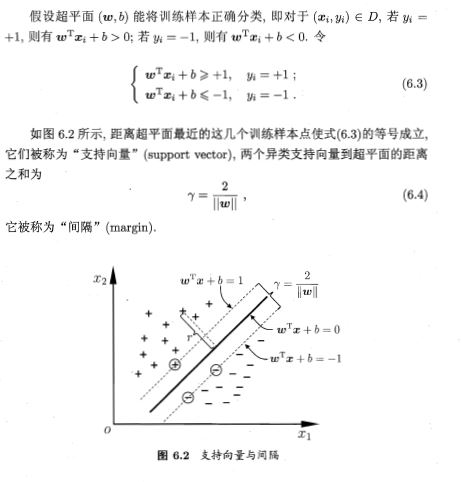
支持向量基本型
最大间隔超平面条件等同于最小化如下公式:
$min_{w,b} \frac{1}{2} \mid \mid \mathbb{w} \mid \mid^2$
s.t. $y_i(\mathbb{w}^T\mathbb{x}_i+b) \ge 1$, i=1,2,...,m.
式(6.6)的约束条件意思是训练样本线性可分,也就是说不存在被分类错误的样本,因此也就不存在欠拟合问题;已知优化式(6.6)目标函数是在寻找“最大间隔”的划分超平面,而“最大间隔”划分超平面所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强,因此可将式(6.6)优化目标进一步解释为寻找最不可能过拟合的分类超平面,这一点与正则化不谋而合。
对偶问题
拉格朗日乘子法
此出假设优化问题一定有解

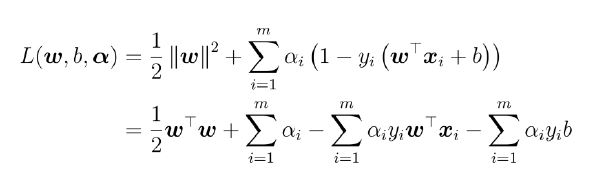



核函数
使训练样本在高维空间可分的映射函数。
 $f(x)=\mathbb{w}^T \phi(x)+b$, 此时w的维度与 $\phi(x)$ 同。
$f(x)=\mathbb{w}^T \phi(x)+b$, 此时w的维度与 $\phi(x)$ 同。
核函数可以分解成两个向量的内积。要想了解某个核函数是如何将原始特征空间映射到更高维的特征空间的,只需要将核函数分解为两个表达形式完全一样的向量 $\phi(x_i)$ 和 $\phi(x_j)$ 即可(有时很难分解)。以下是LIBSVM中的几个核函数:

 遗留问题:核函数的几何意义是什么?核矩阵正定核函数就存在?
遗留问题:核函数的几何意义是什么?核矩阵正定核函数就存在?
软间隔与正则化
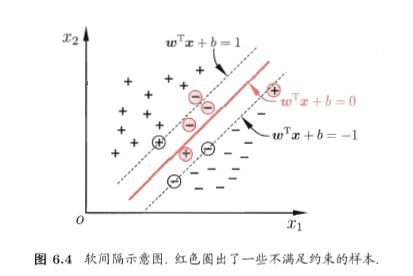
软间隔的引入:
在前面的学习中,一直假设训练样本在样本空间或特征空间是线性可分的,要求所有样本都必须正确划分,称为“硬间隔”,然而现实中很难确定核函数使训练样本线性可分,缓解这一问题的方法是允许SVM在一些样本上出错,因此,引入软间隔:允许某些样本不满足约束 $y_i(w^Tx_i+b) \geq 1$
预备知识:替代损失函数
- 凸函数
- 连续函数
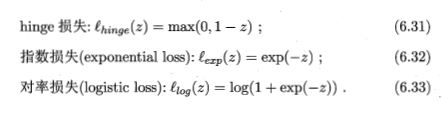
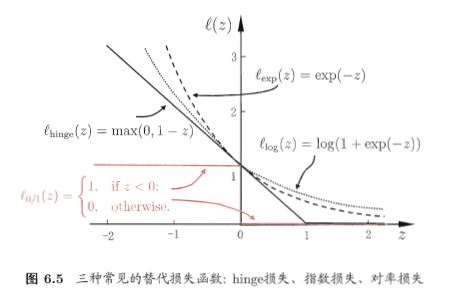
软间隔优化目标函数


引入松弛变量后的目标函数

