AE (auto-encoders)
The schematic structure of an autoencoder is as follows:
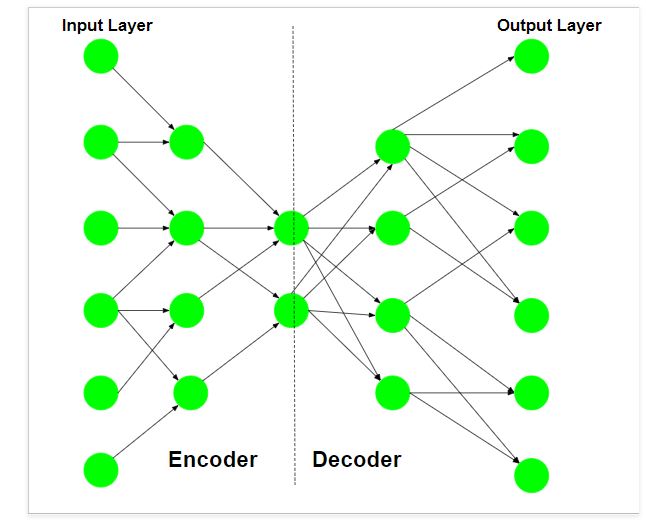 The encoder part of the network is used for encoding and sometimes even for data compression purposes although it is not very effective as compared to other general compression techniques like JPEG.
Encoding is achieved by the encoder part of the network which has decreasing number of hidden units in each layer. Thus this part is forced to pick up only the most significant and representative features of the data.
The encoder part of the network is used for encoding and sometimes even for data compression purposes although it is not very effective as compared to other general compression techniques like JPEG.
Encoding is achieved by the encoder part of the network which has decreasing number of hidden units in each layer. Thus this part is forced to pick up only the most significant and representative features of the data.
The second half of the network performs the Decoding function. This part has the increasing number of hidden units in each layer and thus tries to reconstruct the original input from the encoded data.
AEs are an unsupervised learning technique.
Training of an Auto-encoder for data compression: For a data compression procedure, the most important aspect of the compression is the reliability of the reconstruction of the compressed data. This requirement dictates the structure of the Auto-encoder as a bottleneck.
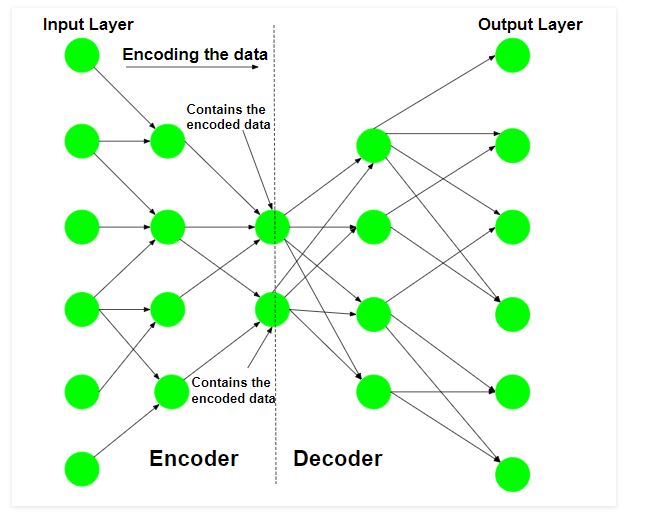
Step 1: Encoding the input data
The Auto-encoder first tries to encode the data using the initialized weights and biases.
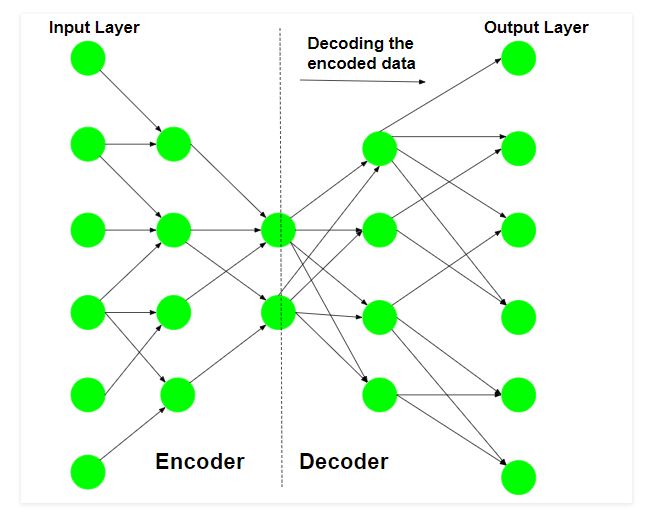
Step 2: Decoding the input data
The Auto-encoder tries to reconstruct the original input from the encoded data to test the reliability of the encoding.
Step 3: Backpropagating the error
After the reconstruction, the loss function is computed to determine the reliability of the encoding. The error generated is backpropagated.
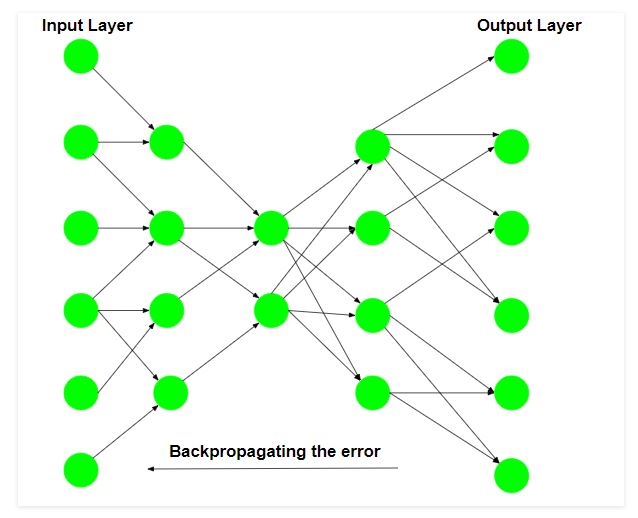 The above-described training process is reiterated several times until an acceptable level of reconstruction is reached.
The above-described training process is reiterated several times until an acceptable level of reconstruction is reached.
After the training process, only the encoder part of the Auto-encoder is retained to encode a similar type of data used in the training process.
The different ways to constrain the network are:
- Keep small Hidden Layers: If the size of each hidden layer is kept as small as possible, then the network will be forced to pick up only the representative features of the data thus encoding the data.
- Regularization: In this method, a loss term is added to the cost function which encourages the network to train in ways other than copying the input.
- Denoising: Another way of constraining the network is to add noise to the input and teaching the network how to remove the noise from the data.
- Tuning the Activation Functions: This method involves changing the activation functions of various nodes so that a majority of the nodes are dormant thus effectively reducing the size of the hidden layers.
The different variations of Auto-encoders are:-
- Denoising Auto-encoder: This type of auto-encoder works on a partially corrupted input and trains to recover the original undistorted image. As mentioned above, this method is an effective way to constrain the network from simply copying the input.
- Sparse Auto-encoder: This type of auto-encoder typically contains more hidden units than the input but only a few are allowed to be active at once. This property is called the sparsity of the network. The sparsity of the network can be controlled by either manually zeroing the required hidden units, tuning the activation functions or by adding a loss term to the cost function.
- Variational Auto-encoder: This type of auto-encoder makes strong assumptions about the distribution of latent variables and uses the Stochastic Gradient Variational Bayes estimator in the training process. It assumes that the data is generated by a Directed Graphical Model and tries to learn an approximation to $q_{\phi}(z|x)$ to the conditional property $q_{\theta}(z|x)$ where $\phi$ and $\theta$ are the parameters of the encoder and the decoder respectively.
DAE
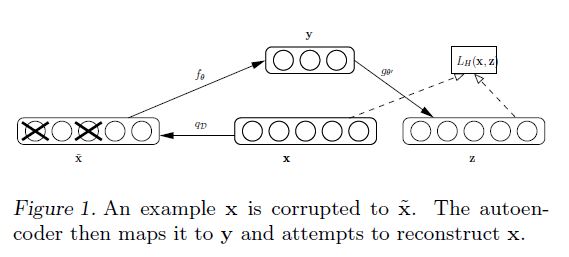
Denoising AutoEncoder(DAE)comes from “Vincent Extracting and composing robust features with denoising autoencoders, 2008”. Its essence is to add noise to the original sample, and the expectation is to use DAE to restore the noise sample to the pure sample.
DAE is a modification to the autoencoder framework to explicitly integrate robustness to partially destroyed inputs.
- corrupt the initial input x to get a partially destroyed version $\hat{x}$ by means of a Stochastic mapping $\hat{x} - q_D(\hat{x} \mid x)$.
- In experiments, we considered the following corrupting process, parameterized by the desired proportion $v$ of “destruction”: for each input x, a fixed number $vd$ of components are chosen at random, and their value is forced to 0, while the others are left untouched. All information about the chosen components is thus removed from that particuler input pattern, and the autoencoder will be trained to “fill-in” these artificially introduced “blanks”.
CDAE
CDAE is a model-based CF method for topN recommendation.
CDAE assumes that whatever user-item interactions are observed are a corrupted version of the user’s full preference set. The model learns latent representations of corrupted user-item preferences that can best reconstruct the full input.
Contribution:
- propose a new model CDAE, which formulates the topN recommendation problem using the Auto-Encoder framework and learns from corrupted inputs. Compared to related methods, CDAE is novel in both model definition and objective function.
- Demonstrate that CDAE is a generalization of several state-of-the-art methods but with a more flexible structure.
- conduct thorough experiments studying the impact of the choices of different components in CDAE, and show that CDAE outperforms state-of-the-art methods on three real world data sets.
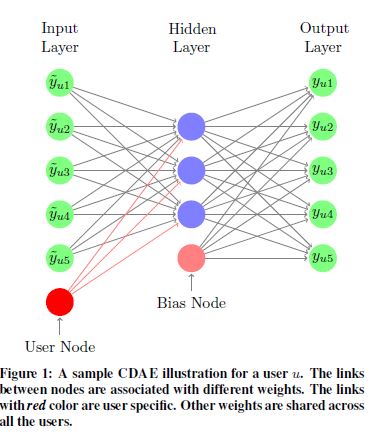
Figure 1 shows a sample structure of CDAE. CDAE consists of 3 layers, including the input layer, the hidden layer and the output layer.
- In the input layer, there are in total I + 1 nodes, where each of the first I nodes corresponds to an item, and the last node is a user specific node (the red node in the figure), which means the node and its associated weights are unique for each user $u \in U$ in the data. We refer to the first I nodes as item input nodes, and the last node as user input node. Given the historical feedback.
- There are K nodes in the hidden layer and these nodes are fully connected to the nodes of the input layer. Here K is a predefined constant which is usually much smaller than the size of the input vectors. The hidden layer also has an additional node to model the bias effects (the pink node in the figure).
- In the output layer, there are I nodes representing reconstructions of the input vector yu. The nodes in the output layer are fully connected with nodes in the hidden layer.
Formally, the inputs of CDAE are the corrupted feedback vector $\hat{y}_u$ which is generated from $p(\hat{y}_u \mid y_u)$ as stated in Equation 9. Intuitively, the non-zero values in $y_u$ are randomly dropped out independently with probability q. The resulting vector $\hat{y}_u$ is still a sparse vector, where the indexes of the non-zero values are a subset of those of the original vector.
- CDAE first maps the input to a latent representations $z_u$: $z_u=h(W^\top\hat{y}_u+V_u+b)$,
- At the output layer, the latent representation is then mapped back to the original input space to reconstruct the input vector. The output value $\hat{y}{ui}$ for node i is computed as follows: $\hat{y}{ui}=f(W^{'\top}_{i}z_u+b^{'}_i)$,
- minimizing the average loss.
Trust-aware CDAE
This paper utilize CDAE to tackle data sparsity and cold start to learn compact and effective representations from both rating and trust data for top-N recommendation.
This motivate us to propose the TDAE model, which utilizes Denoising Auto-Encoder model to learn exactly user preferences from both of rating and trust data.
Motivations:
- First, most of them model the trust relationships with shallow model and ignore the high-order interactions among each users’ friends; it is possible for a user to take all the opinions of his friends into account and then come out his own thinking rather than linearly combine all of them.
- Second, the trust relationships are also facing the sparse problem as well as ratings. This may limits the improvement of trust-aware algorithms and make it difficult to utilize deep model to learn high-order information from trust data.
Contribution
- In this paper, we propose a novel deep learning model to learn user preferences from rating and trust data. Toward the big challenge of data sparse for this problem, the TDAE model is built by fusing two denoising autoencoders with a weighted layer, which is used to balance the importance of rating and trust data. This model can also easily be extended for other recommendation tasks with additional information.
- To keep away from overfitting, we further propose a correlative regularization to constraint the learning process. Since we model user preferences in two perspectives, we argue that they can be used to predict each other to a certain degree. This motivate us to propose the Correlative regularization to build relations between the layers in same level. This regularization can efficient improve the effectiveness and robust of TDAE model.
- We conduct comprehensive experiments with two datasets to compare our approach with state-of-the-art algorithms on Top-N recommendation task. There are several works show clearly that Top-N recommendation is more close to real application scenarios than rating prediction. So we adopt ranking-sensitive metrics to evaluate the TDAE model, i.e., MAP and NDCG. The results demonstrate that our model significant outperform other comparisons, and is further improved by incorporating correlative regularization.
- Trust-aware Recommendation: SocialMF, SoReg, TrustMF, TrustSVD, However, all these methods utilize trust data in shallow level and ignore the factor that trust relationships are very complex.
- Deep Learning for Recommendation: rating-based methods and auxiliary data based methods.
- Topn recommendation: